Keywords and collocation analysis on the BASE corpus
Based on Dirk Speelman’s course material
1 Setup
This document illustrates a keyword analysis and a collocation analysis. They both use the BASE corpus and the same criteria for association strength.
For the analysis we’ll mainly use the tidyverse package and the mclm package. We’ll also use here to find the corpus and, for the report itself when printing tables, kableExtra.
1.1 Association strength criteria
Both of the studies rely on the assoc_scores objects of the mclm package, which return frequencies and association scores, i.e. measures based on the frequency of a certain event in a target context and in a reference context. For keyword analysis, the target context is a target (sub)corpus and the reference context is a reference (sub)corpus. For collocation analysis based on surface co-occurrences, the target context is the text surrounding the occurrences of the node term and the reference context is all the other text in the corpus.
In order to define keywords (for the first study) or collocations (for the second study) we will filter the output of assoc_scores() based on the following three criteria:
- A frequency of three or higher in the target context.
- A PMI score of two or higher.
- A signed G score of two or higher.
A PMI score of two or higher means that the probability of the keyword in the target context is at least four times higher than its probability in all the data taken together.
Remember that, as a strength of evidence measure, \(G^2\) is higher when there is more evidence that two words are not independent, but it does not distinguish between attraction and repulsion. Therefore, a signed G score as returned by assoc_scores() is a modification that adds a minus to \(G^2\) when the observed frequency of the event is lower than its expected frequency. A threshold of two or higher is not a very strict criterion. With a signed \(G^2\) of 2 there is only mild evidence for attraction. In a traditional \(G\) test (log likelihood ratio test) for a two-by-two contingency table, a \(G^2\) score of 1 would indicate no evidence for any association whatsoever and a \(G^2\) score of 3.84 would be needed for the test to indicate a significant association (at a 95% confidence level). So a value of 2 would indicate that there is not enough evidence to establish significance.
In short, the selection criteria that were chosen here value both the effect size and amount of evidence, but could be said to be more demanding with respect to the former than with respect to the latter. This choice is acceptable, as long as the researcher is aware to be prioritizing (to some extent) effect size over amount of evidence.
1.2 Data
The first step to analyzing the data is to read the corpus. The first line of the code below sets the path to the “BASE” directory where all the corpus files are stored, in this case inside a “_corpora” folder, inside a “studies” folder at the top level of the project. In order to run this in your own computer, set corpus_folder to the path to where your copy of the corpus is stored (inside your project).
The second line of the code collects all the file names in that folder in an fnames object and keeps those with the “txt” extension.
hide_path argument in the print() method for an fnames object allows us to hide a (redundant) bit of the filenames when printing them.corpus_folder <- here("studies", "_corpora", "BASE")
fnames_BASE <- get_fnames(corpus_folder) %>%
keep_re("[.]txt")
print(fnames_BASE, 10, hide_path = corpus_folder)Filename collection of length 198
filename
-------------------
1 txt/ah/ahlct001.txt
2 txt/ah/ahlct002.txt
3 txt/ah/ahlct003.txt
4 txt/ah/ahlct004.txt
5 txt/ah/ahlct005.txt
6 txt/ah/ahlct006.txt
7 txt/ah/ahlct007.txt
8 txt/ah/ahlct008.txt
9 txt/ah/ahlct009.txt
10 txt/ah/ahlct010.txt
...The functions to actually read the corpus for the analyses will be freqlist() and surf_cooc(). In both cases we’ll use three non-default settings that are more appropriate for the format of the BASE corpus.
- In
re_token_splitterwe use the regular expression\s+; in other words, we treat all chunks of whitespace as token separators. We do this because the default tokenizer, which roughly identifies the chunks of alphanumeric characters as tokens, would e.g. cut up the corpus snippeta simple [0.4] exampleinto the tokensa,simple,0,4, andexample, which is not what we want. The tokenizer we do use would cut the same snippet up in the tokensa,simple,[0.4], andexample. This is still not exactly what we want, but see the next point. - In
re_drop_tokenwe use[:\[\]]in order to drop all the tokens that match this regular expression; in other words we drop all tokens that contain either a colon, an opening square bracket or a closing square bracket. So, in the aforementioned example, the pseudo-token[0.4], which actually is a pause indication, would be dropped eventually. Tokens that contain a colon are also dropped, because those are speaker identifiers in the BASE corpus, not real tokens. - In
file_encodingwe specifywindows-1252, which indeed is the encoding used in the BASE corpus.
1.3 Steps
The main function we will use is assoc_scores(), which creates an object of class assoc_scores, i.e. a special kind of dataframe with association scores information. In the case of keyword analysis (Section 2) we’ll run it with two frequency lists created from different subcorpora, whereas for collocation analysis (Section 3) we’ll provide a cooc_info object created with surf_cooc().
By default, assoc_scores() will not return values where the frequency in the target context was lower than 3, so we don’t need to do anything else to define our first criterion. For the other two criteria, instead, we’ll need to filter the assoc_scores object to only retain elements with a high enough PMI and G signed. Section 4 will illustrates steps to follow that are common to both workflows.
2 Keyword analysis
For the keyword analysis, the target corpus will be the file ahlct001.txt, and the reference corpus, the remaining 198 files of our corpus. We will store the target filename in a variable called fnames_target and the reference corpus filenames in a variable called fnames_ref.
# store names of target corpus files in fnames_target
fnames_target <- fnames_BASE %>%
keep_re("ahlct001") %>%
print(hide_path = corpus_folder)Filename collection of length 1
filename
-------------------
1 txt/ah/ahlct001.txt# store names of reference corpus files in fnames_ref
fnames_ref <- fnames_BASE %>%
drop_re("ahlct001") %>%
print(n = 10, hide_path = corpus_folder)Filename collection of length 197
filename
-------------------
1 txt/ah/ahlct002.txt
2 txt/ah/ahlct003.txt
3 txt/ah/ahlct004.txt
4 txt/ah/ahlct005.txt
5 txt/ah/ahlct006.txt
6 txt/ah/ahlct007.txt
7 txt/ah/ahlct008.txt
8 txt/ah/ahlct009.txt
9 txt/ah/ahlct010.txt
10 txt/ah/ahlct011.txt
...2.1 Frequency lists
Next, we build the frequency lists, both for the target corpus and for the reference corpus. The former we store in a variable flist_target and the latter in a variable flist_ref.
In both cases we’ll use raw strings for the regular expressions, although they are a bit of an overkill with such simple expressions. We do it out of principle, to get used to their syntax.
# build frequency list for target corpus
flist_target <- fnames_target %>%
freqlist(re_token_splitter = r"--[(?xi) \s+ ]--", # whitespace as token splitter
re_drop_token = r"--[(?xi) [:\[\]] ]--", # drop tokens with :, [ or ]
file_encoding = "windows-1252") %>%
print()
# build frequency list for reference corpus
flist_ref <- fnames_ref %>%
freqlist(re_token_splitter = r"--[(?xi) \s+ ]--",
re_drop_token = r"--[(?xi) [:\[\]] ]--",
file_encoding = "windows-1252") %>%
print()Frequency list (types in list: 2528, tokens in list: 10361)
rank type abs_freq nrm_freq
---- ---- -------- --------
1 the 595 574.3
2 of 336 324.3
3 and 319 307.9
4 a 277 267.3
5 to 248 239.4
6 in 216 208.5
7 er 175 168.9
8 i 168 162.1
9 you 118 113.9
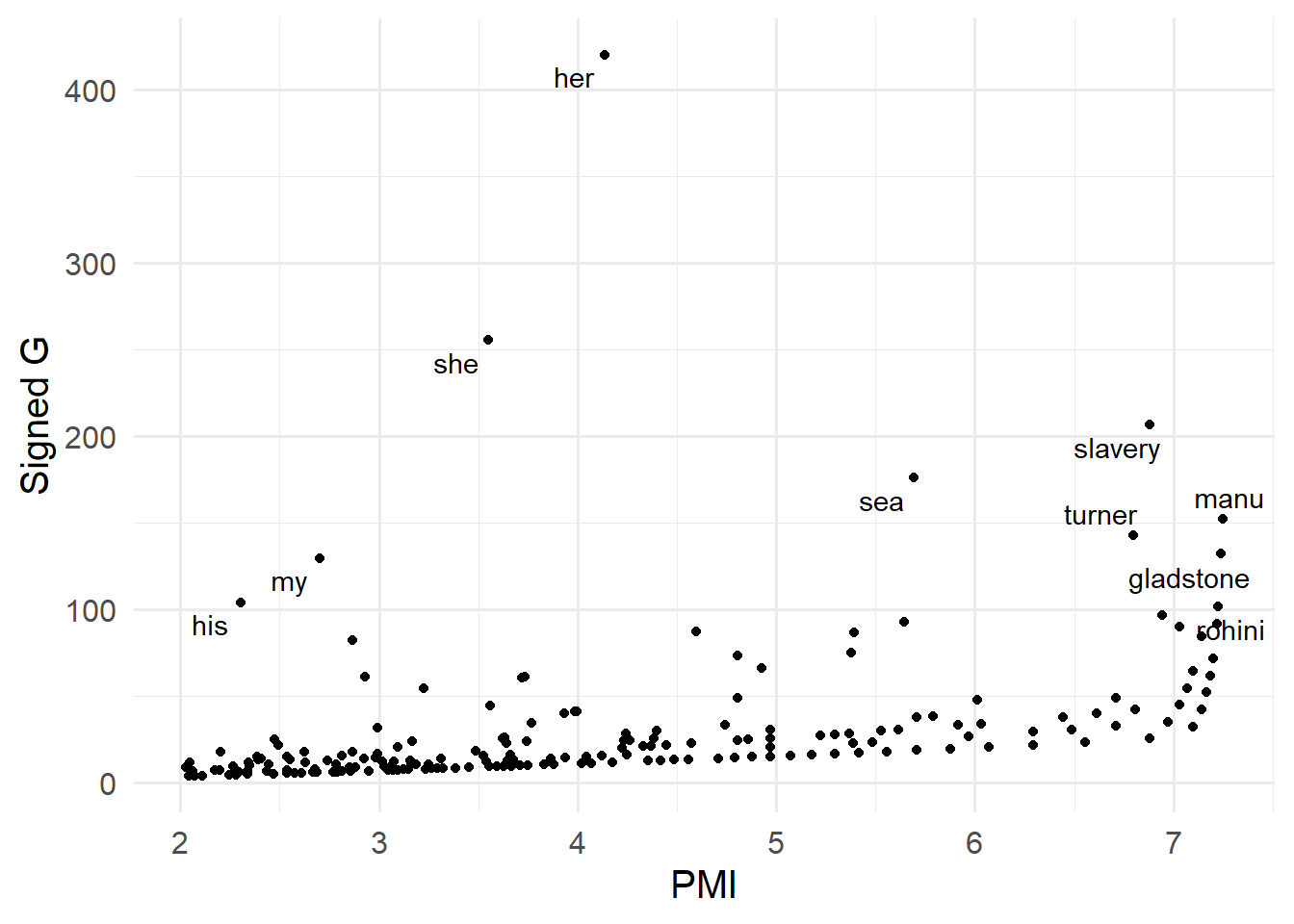
10 her 106 102.3
11 he 102 98.4
12 was 102 98.4
13 is 96 92.7
14 she 81 78.2
15 that 81 78.2
16 it 78 75.3
17 with 71 68.5
18 as 64 61.8
19 for 64 61.8
20 his 64 61.8
...Frequency list (types in list: 36491, tokens in list: 1614252)
rank type abs_freq nrm_freq
---- ---- -------- --------
1 the 86625 536.6
2 of 48929 303.1
3 and 44915 278.2
4 to 42614 264.0
5 er 39352 243.8
6 a 36154 224.0
7 that 31807 197.0
8 in 30177 186.9
9 you 29426 182.3
10 is 25986 161.0
11 it 20365 126.2
12 so 16849 104.4
13 i 16757 103.8
14 this 14907 92.3
15 we 13097 81.1
16 have 10326 64.0
17 what 10261 63.6
18 on 10183 63.1
19 be 10177 63.0
20 but 10134 62.8
...We can turn freqlist objects into tibbles and print them nicely with kableExtra. When the output is HTML, we can also print the table in a scrollable box, like in Table 1.
flist_target %>%
as_tibble() %>%
kbl(col.names = c("Rank", "Type", "Absolute", "Relative")) %>%
kable_minimal(full_width = FALSE) %>%
add_header_above(c(" " = 2, "Frequency" = 2)) %>%
scroll_box(height = "400px")Frequency |
|||
|---|---|---|---|
| Rank | Type | Absolute | Relative |
| 1 | the | 595 | 574.269 |
| 2 | of | 336 | 324.293 |
| 3 | and | 319 | 307.885 |
| 4 | a | 277 | 267.349 |
| 5 | to | 248 | 239.359 |
| 6 | in | 216 | 208.474 |
| 7 | er | 175 | 168.903 |
| 8 | i | 168 | 162.147 |
| 9 | you | 118 | 113.889 |
| 10 | her | 106 | 102.307 |
| 11 | he | 102 | 98.446 |
| 12 | was | 102 | 98.446 |
| 13 | is | 96 | 92.655 |
| 14 | she | 81 | 78.178 |
| 15 | that | 81 | 78.178 |
| 16 | it | 78 | 75.282 |
| 17 | with | 71 | 68.526 |
| 18 | as | 64 | 61.770 |
| 19 | for | 64 | 61.770 |
| 20 | his | 64 | 61.770 |
| 21 | my | 62 | 59.840 |
| 22 | this | 61 | 58.875 |
| 23 | at | 59 | 56.944 |
| 24 | from | 58 | 55.979 |
| 25 | we | 58 | 55.979 |
| 26 | about | 56 | 54.049 |
| 27 | so | 56 | 54.049 |
| 28 | by | 53 | 51.153 |
| 29 | it's | 48 | 46.328 |
| 30 | on | 47 | 45.362 |
| 31 | but | 46 | 44.397 |
| 32 | know | 46 | 44.397 |
| 33 | up | 44 | 42.467 |
| 34 | when | 44 | 42.467 |
| 35 | have | 37 | 35.711 |
| 36 | all | 36 | 34.746 |
| 37 | him | 36 | 34.746 |
| 38 | like | 35 | 33.781 |
| 39 | me | 34 | 32.815 |
| 40 | they | 34 | 32.815 |
| 41 | or | 32 | 30.885 |
| 42 | what | 32 | 30.885 |
| 43 | which | 32 | 30.885 |
| 44 | no | 31 | 29.920 |
| 45 | not | 30 | 28.955 |
| 46 | had | 29 | 27.990 |
| 47 | their | 29 | 27.990 |
| 48 | who | 29 | 27.990 |
| 49 | into | 28 | 27.024 |
| 50 | sea | 28 | 27.024 |
| 51 | be | 27 | 26.059 |
| 52 | do | 27 | 26.059 |
| 53 | kind | 27 | 26.059 |
| 54 | out | 26 | 25.094 |
| 55 | write | 26 | 25.094 |
| 56 | our | 25 | 24.129 |
| 57 | right | 25 | 24.129 |
| 58 | slavery | 24 | 23.164 |
| 59 | them | 24 | 23.164 |
| 60 | will | 24 | 23.164 |
| 61 | an | 23 | 22.199 |
| 62 | more | 23 | 22.199 |
| 63 | yeah | 23 | 22.199 |
| 64 | could | 22 | 21.233 |
| 65 | very | 22 | 21.233 |
| 66 | because | 21 | 20.268 |
| 67 | called | 21 | 20.268 |
| 68 | where | 21 | 20.268 |
| 69 | would | 21 | 20.268 |
| 70 | are | 20 | 19.303 |
| 71 | man | 20 | 19.303 |
| 72 | only | 20 | 19.303 |
| 73 | some | 20 | 19.303 |
| 74 | then | 20 | 19.303 |
| 75 | dead | 19 | 18.338 |
| 76 | each | 19 | 18.338 |
| 77 | now | 19 | 18.338 |
| 78 | us | 19 | 18.338 |
| 79 | way | 19 | 18.338 |
| 80 | has | 18 | 17.373 |
| 81 | land | 18 | 17.373 |
| 82 | there | 18 | 17.373 |
| 83 | white | 18 | 17.373 |
| 84 | you're | 18 | 17.373 |
| 85 | first | 17 | 16.408 |
| 86 | if | 17 | 16.408 |
| 87 | one | 17 | 16.408 |
| 88 | turner | 17 | 16.408 |
| 89 | another | 16 | 15.443 |
| 90 | before | 16 | 15.443 |
| 91 | down | 16 | 15.443 |
| 92 | just | 16 | 15.443 |
| 93 | through | 16 | 15.443 |
| 94 | african | 15 | 14.477 |
| 95 | come | 15 | 14.477 |
| 96 | great | 15 | 14.477 |
| 97 | manu | 15 | 14.477 |
| 98 | poem | 15 | 14.477 |
| 99 | shop | 15 | 14.477 |
| 100 | even | 14 | 13.512 |
| 101 | face | 14 | 13.512 |
| 102 | he's | 14 | 13.512 |
| 103 | say | 14 | 13.512 |
| 104 | wanted | 14 | 13.512 |
| 105 | can't | 13 | 12.547 |
| 106 | fish | 13 | 12.547 |
| 107 | gladstone | 13 | 12.547 |
| 108 | men | 13 | 12.547 |
| 109 | mouth | 13 | 12.547 |
| 110 | over | 13 | 12.547 |
| 111 | than | 13 | 12.547 |
| 112 | your | 13 | 12.547 |
| 113 | after | 12 | 11.582 |
| 114 | can | 12 | 11.582 |
| 115 | going | 12 | 11.582 |
| 116 | hand | 12 | 11.582 |
| 117 | other | 12 | 11.582 |
| 118 | think | 12 | 11.582 |
| 119 | time | 12 | 11.582 |
| 120 | were | 12 | 11.582 |
| 121 | writing | 12 | 11.582 |
| 122 | don't | 11 | 10.617 |
| 123 | go | 11 | 10.617 |
| 124 | language | 11 | 10.617 |
| 125 | love | 11 | 10.617 |
| 126 | nigger | 11 | 10.617 |
| 127 | novel | 11 | 10.617 |
| 128 | off | 11 | 10.617 |
| 129 | painting | 11 | 10.617 |
| 130 | sense | 11 | 10.617 |
| 131 | something | 11 | 10.617 |
| 132 | well | 11 | 10.617 |
| 133 | get | 10 | 9.652 |
| 134 | passage | 10 | 9.652 |
| 135 | people | 10 | 9.652 |
| 136 | really | 10 | 9.652 |
| 137 | rohini | 10 | 9.652 |
| 138 | see | 10 | 9.652 |
| 139 | sex | 10 | 9.652 |
| 140 | shah | 10 | 9.652 |
| 141 | still | 10 | 9.652 |
| 142 | words | 10 | 9.652 |
| 143 | years | 10 | 9.652 |
| 144 | back | 9 | 8.686 |
| 145 | being | 9 | 8.686 |
| 146 | black | 9 | 8.686 |
| 147 | century | 9 | 8.686 |
| 148 | child | 9 | 8.686 |
| 149 | did | 9 | 8.686 |
| 150 | end | 9 | 8.686 |
| 151 | guyana | 9 | 8.686 |
| 152 | here | 9 | 8.686 |
| 153 | reading | 9 | 8.686 |
| 154 | said | 9 | 8.686 |
| 155 | should | 9 | 8.686 |
| 156 | that's | 9 | 8.686 |
| 157 | there's | 9 | 8.686 |
| 158 | thought | 9 | 8.686 |
| 159 | troilus | 9 | 8.686 |
| 160 | two | 9 | 8.686 |
| 161 | until | 9 | 8.686 |
| 162 | whole | 9 | 8.686 |
| 163 | yes | 9 | 8.686 |
| 164 | against | 8 | 7.721 |
| 165 | around | 8 | 7.721 |
| 166 | behind | 8 | 7.721 |
| 167 | felt | 8 | 7.721 |
| 168 | hands | 8 | 7.721 |
| 169 | himself | 8 | 7.721 |
| 170 | i'm | 8 | 7.721 |
| 171 | its | 8 | 7.721 |
| 172 | most | 8 | 7.721 |
| 173 | mother | 8 | 7.721 |
| 174 | old | 8 | 7.721 |
| 175 | own | 8 | 7.721 |
| 176 | read | 8 | 7.721 |
| 177 | these | 8 | 7.721 |
| 178 | too | 8 | 7.721 |
| 179 | took | 8 | 7.721 |
| 180 | why | 8 | 7.721 |
| 181 | woman | 8 | 7.721 |
| 182 | work | 8 | 7.721 |
| 183 | awakened | 7 | 6.756 |
| 184 | been | 7 | 6.756 |
| 185 | between | 7 | 6.756 |
| 186 | blood | 7 | 6.756 |
| 187 | body | 7 | 6.756 |
| 188 | came | 7 | 6.756 |
| 189 | caught | 7 | 6.756 |
| 190 | earth | 7 | 6.756 |
| 191 | got | 7 | 6.756 |
| 192 | head | 7 | 6.756 |
| 193 | home | 7 | 6.756 |
| 194 | latin | 7 | 6.756 |
| 195 | left | 7 | 6.756 |
| 196 | live | 7 | 6.756 |
| 197 | many | 7 | 6.756 |
| 198 | mean | 7 | 6.756 |
| 199 | much | 7 | 6.756 |
| 200 | myself | 7 | 6.756 |
| 201 | reached | 7 | 6.756 |
| 202 | saw | 7 | 6.756 |
| 203 | ship | 7 | 6.756 |
| 204 | space | 7 | 6.756 |
| 205 | things | 7 | 6.756 |
| 206 | thistlewood | 7 | 6.756 |
| 207 | used | 7 | 6.756 |
| 208 | village | 7 | 6.756 |
| 209 | we're | 7 | 6.756 |
| 210 | again | 6 | 5.791 |
| 211 | always | 6 | 5.791 |
| 212 | anyway | 6 | 5.791 |
| 213 | away | 6 | 5.791 |
| 214 | beauty | 6 | 5.791 |
| 215 | big | 6 | 5.791 |
| 216 | book | 6 | 5.791 |
| 217 | breath | 6 | 5.791 |
| 218 | british | 6 | 5.791 |
| 219 | centre | 6 | 5.791 |
| 220 | classics | 6 | 5.791 |
| 221 | desire | 6 | 5.791 |
| 222 | eighteenth | 6 | 5.791 |
| 223 | english | 6 | 5.791 |
| 224 | estate | 6 | 5.791 |
| 225 | eyes | 6 | 5.791 |
| 226 | family | 6 | 5.791 |
| 227 | god | 6 | 5.791 |
| 228 | guyanese | 6 | 5.791 |
| 229 | house | 6 | 5.791 |
| 230 | how | 6 | 5.791 |
| 231 | idea | 6 | 5.791 |
| 232 | instead | 6 | 5.791 |
| 233 | last | 6 | 5.791 |
| 234 | life | 6 | 5.791 |
| 235 | look | 6 | 5.791 |
| 236 | looked | 6 | 5.791 |
| 237 | made | 6 | 5.791 |
| 238 | makes | 6 | 5.791 |
| 239 | miriam | 6 | 5.791 |
| 240 | moon | 6 | 5.791 |
| 241 | namex | 6 | 5.791 |
| 242 | new | 6 | 5.791 |
| 243 | night | 6 | 5.791 |
| 244 | once | 6 | 5.791 |
| 245 | place | 6 | 5.791 |
| 246 | pounds | 6 | 5.791 |
| 247 | stillborn | 6 | 5.791 |
| 248 | utterly | 6 | 5.791 |
| 249 | want | 6 | 5.791 |
| 250 | water | 6 | 5.791 |
| 251 | went | 6 | 5.791 |
| 252 | without | 6 | 5.791 |
| 253 | women | 6 | 5.791 |
| 254 | wrote | 6 | 5.791 |
| 255 | 'cause | 5 | 4.826 |
| 256 | abandoned | 5 | 4.826 |
| 257 | across | 5 | 4.826 |
| 258 | among | 5 | 4.826 |
| 259 | ancestry | 5 | 4.826 |
| 260 | animals | 5 | 4.826 |
| 261 | becomes | 5 | 4.826 |
| 262 | boy | 5 | 4.826 |
| 263 | bush | 5 | 4.826 |
| 264 | cabin | 5 | 4.826 |
| 265 | captain | 5 | 4.826 |
| 266 | colours | 5 | 4.826 |
| 267 | curtain | 5 | 4.826 |
| 268 | day | 5 | 4.826 |
| 269 | different | 5 | 4.826 |
| 270 | doing | 5 | 4.826 |
| 271 | drowned | 5 | 4.826 |
| 272 | except | 5 | 4.826 |
| 273 | flesh | 5 | 4.826 |
| 274 | gave | 5 | 4.826 |
| 275 | imagination | 5 | 4.826 |
| 276 | indian | 5 | 4.826 |
| 277 | kampta | 5 | 4.826 |
| 278 | looking | 5 | 4.826 |
| 279 | magazine | 5 | 4.826 |
| 280 | marginal | 5 | 4.826 |
| 281 | matter | 5 | 4.826 |
| 282 | miles | 5 | 4.826 |
| 283 | nothing | 5 | 4.826 |
| 284 | pages | 5 | 4.826 |
| 285 | passages | 5 | 4.826 |
| 286 | peripheral | 5 | 4.826 |
| 287 | plantation | 5 | 4.826 |
| 288 | plot | 5 | 4.826 |
| 289 | put | 5 | 4.826 |
| 290 | rage | 5 | 4.826 |
| 291 | servant | 5 | 4.826 |
| 292 | set | 5 | 4.826 |
| 293 | skin | 5 | 4.826 |
| 294 | sky | 5 | 4.826 |
| 295 | slave | 5 | 4.826 |
| 296 | slipped | 5 | 4.826 |
| 297 | small | 5 | 4.826 |
| 298 | sometimes | 5 | 4.826 |
| 299 | source | 5 | 4.826 |
| 300 | stone | 5 | 4.826 |
| 301 | storm | 5 | 4.826 |
| 302 | story | 5 | 4.826 |
| 303 | subject | 5 | 4.826 |
| 304 | sun | 5 | 4.826 |
| 305 | terms | 5 | 4.826 |
| 306 | they're | 5 | 4.826 |
| 307 | today | 5 | 4.826 |
| 308 | towards | 5 | 4.826 |
| 309 | tribe | 5 | 4.826 |
| 310 | upon | 5 | 4.826 |
| 311 | whatever | 5 | 4.826 |
| 312 | within | 5 | 4.826 |
| 313 | actually | 4 | 3.861 |
| 314 | air | 4 | 3.861 |
| 315 | am | 4 | 3.861 |
| 316 | amazonian | 4 | 3.861 |
| 317 | anarch | 4 | 3.861 |
| 318 | aperture | 4 | 3.861 |
| 319 | art | 4 | 3.861 |
| 320 | asked | 4 | 3.861 |
| 321 | basically | 4 | 3.861 |
| 322 | bearing | 4 | 3.861 |
| 323 | beyond | 4 | 3.861 |
| 324 | break | 4 | 3.861 |
| 325 | caesar | 4 | 3.861 |
| 326 | call | 4 | 3.861 |
| 327 | case | 4 | 3.861 |
| 328 | coins | 4 | 3.861 |
| 329 | colour | 4 | 3.861 |
| 330 | coming | 4 | 3.861 |
| 331 | coolie | 4 | 3.861 |
| 332 | course | 4 | 3.861 |
| 333 | cries | 4 | 3.861 |
| 334 | criseyde | 4 | 3.861 |
| 335 | darkness | 4 | 3.861 |
| 336 | deep | 4 | 3.861 |
| 337 | didn't | 4 | 3.861 |
| 338 | ears | 4 | 3.861 |
| 339 | ellar | 4 | 3.861 |
| 340 | entered | 4 | 3.861 |
| 341 | fall | 4 | 3.861 |
| 342 | five | 4 | 3.861 |
| 343 | flooded | 4 | 3.861 |
| 344 | floor | 4 | 3.861 |
| 345 | future | 4 | 3.861 |
| 346 | good | 4 | 3.861 |
| 347 | grandpa | 4 | 3.861 |
| 348 | greatest | 4 | 3.861 |
| 349 | ground | 4 | 3.861 |
| 350 | i'll | 4 | 3.861 |
| 351 | i-, | 4 | 3.861 |
| 352 | jungle | 4 | 3.861 |
| 353 | kaka | 4 | 3.861 |
| 354 | knew | 4 | 3.861 |
| 355 | lachrimae | 4 | 3.861 |
| 356 | lay | 4 | 3.861 |
| 357 | let | 4 | 3.861 |
| 358 | lets | 4 | 3.861 |
| 359 | lies | 4 | 3.861 |
| 360 | little | 4 | 3.861 |
| 361 | long | 4 | 3.861 |
| 362 | longer | 4 | 3.861 |
| 363 | lot | 4 | 3.861 |
| 364 | might | 4 | 3.861 |
| 365 | mind | 4 | 3.861 |
| 366 | mine | 4 | 3.861 |
| 367 | must | 4 | 3.861 |
| 368 | never | 4 | 3.861 |
| 369 | nor | 4 | 3.861 |
| 370 | obviously | 4 | 3.861 |
| 371 | overboard | 4 | 3.861 |
| 372 | perhaps | 4 | 3.861 |
| 373 | periphery | 4 | 3.861 |
| 374 | pond | 4 | 3.861 |
| 375 | probably | 4 | 3.861 |
| 376 | rains | 4 | 3.861 |
| 377 | reach | 4 | 3.861 |
| 378 | s-, | 4 | 3.861 |
| 379 | slaves | 4 | 3.861 |
| 380 | someone | 4 | 3.861 |
| 381 | speak | 4 | 3.861 |
| 382 | speech | 4 | 3.861 |
| 383 | stars | 4 | 3.861 |
| 384 | strength | 4 | 3.861 |
| 385 | sudden | 4 | 3.861 |
| 386 | surface | 4 | 3.861 |
| 387 | tell | 4 | 3.861 |
| 388 | therefore | 4 | 3.861 |
| 389 | those | 4 | 3.861 |
| 390 | trying | 4 | 3.861 |
| 391 | turner's | 4 | 3.861 |
| 392 | use | 4 | 3.861 |
| 393 | waters | 4 | 3.861 |
| 394 | ways | 4 | 3.861 |
| 395 | we'll | 4 | 3.861 |
| 396 | who's | 4 | 3.861 |
| 397 | abandons | 3 | 2.895 |
| 398 | accompany | 3 | 2.895 |
| 399 | accountant | 3 | 2.895 |
| 400 | africa | 3 | 2.895 |
| 401 | afterwards | 3 | 2.895 |
| 402 | aggressive | 3 | 2.895 |
| 403 | almost | 3 | 2.895 |
| 404 | along | 3 | 2.895 |
| 405 | any | 3 | 2.895 |
| 406 | area | 3 | 2.895 |
| 407 | beatings | 3 | 2.895 |
| 408 | beautiful | 3 | 2.895 |
| 409 | begin | 3 | 2.895 |
| 410 | below | 3 | 2.895 |
| 411 | bleak | 3 | 2.895 |
| 412 | bloody | 3 | 2.895 |
| 413 | booths | 3 | 2.895 |
| 414 | boys | 3 | 2.895 |
| 415 | bright | 3 | 2.895 |
| 416 | brown | 3 | 2.895 |
| 417 | bury | 3 | 2.895 |
| 418 | caribbean | 3 | 2.895 |
| 419 | carries | 3 | 2.895 |
| 420 | catch | 3 | 2.895 |
| 421 | cemetery | 3 | 2.895 |
| 422 | close | 3 | 2.895 |
| 423 | closed | 3 | 2.895 |
| 424 | collapsed | 3 | 2.895 |
| 425 | coloured | 3 | 2.895 |
| 426 | counting | 3 | 2.895 |
| 427 | culture | 3 | 2.895 |
| 428 | curse | 3 | 2.895 |
| 429 | dangerous | 3 | 2.895 |
| 430 | desperation | 3 | 2.895 |
| 431 | die | 3 | 2.895 |
| 432 | diomede | 3 | 2.895 |
| 433 | direction | 3 | 2.895 |
| 434 | distance | 3 | 2.895 |
| 435 | dragged | 3 | 2.895 |
| 436 | dry | 3 | 2.895 |
| 437 | early | 3 | 2.895 |
| 438 | effort | 3 | 2.895 |
| 439 | eighteen-forty | 3 | 2.895 |
| 440 | ellar's | 3 | 2.895 |
| 441 | endlessly | 3 | 2.895 |
| 442 | england | 3 | 2.895 |
| 443 | enormously | 3 | 2.895 |
| 444 | enough | 3 | 2.895 |
| 445 | entering | 3 | 2.895 |
| 446 | examiner | 3 | 2.895 |
| 447 | eye | 3 | 2.895 |
| 448 | faces | 3 | 2.895 |
| 449 | fat | 3 | 2.895 |
| 450 | father | 3 | 2.895 |
| 451 | feet | 3 | 2.895 |
| 452 | few | 3 | 2.895 |
| 453 | fifty | 3 | 2.895 |
| 454 | footnotes | 3 | 2.895 |
| 455 | form | 3 | 2.895 |
| 456 | found | 3 | 2.895 |
| 457 | four | 3 | 2.895 |
| 458 | friend | 3 | 2.895 |
| 459 | full | 3 | 2.895 |
| 460 | gets | 3 | 2.895 |
| 461 | giving | 3 | 2.895 |
| 462 | gladstone's | 3 | 2.895 |
| 463 | gods | 3 | 2.895 |
| 464 | goes | 3 | 2.895 |
| 465 | grasp | 3 | 2.895 |
| 466 | grave | 3 | 2.895 |
| 467 | grotesque | 3 | 2.895 |
| 468 | grows | 3 | 2.895 |
| 469 | guidance | 3 | 2.895 |
| 470 | happened | 3 | 2.895 |
| 471 | hear | 3 | 2.895 |
| 472 | historic | 3 | 2.895 |
| 473 | history | 3 | 2.895 |
| 474 | hundred | 3 | 2.895 |
| 475 | i've | 3 | 2.895 |
| 476 | jamaican | 3 | 2.895 |
| 477 | killed | 3 | 2.895 |
| 478 | learn | 3 | 2.895 |
| 479 | learning | 3 | 2.895 |
| 480 | least | 3 | 2.895 |
| 481 | leave | 3 | 2.895 |
| 482 | legs | 3 | 2.895 |
| 483 | less | 3 | 2.895 |
| 484 | light | 3 | 2.895 |
| 485 | london | 3 | 2.895 |
| 486 | make | 3 | 2.895 |
| 487 | melody | 3 | 2.895 |
| 488 | memory | 3 | 2.895 |
| 489 | minutes | 3 | 2.895 |
| 490 | miriam's | 3 | 2.895 |
| 491 | mist | 3 | 2.895 |
| 492 | money | 3 | 2.895 |
| 493 | motive | 3 | 2.895 |
| 494 | mrs | 3 | 2.895 |
| 495 | name | 3 | 2.895 |
| 496 | neck | 3 | 2.895 |
| 497 | onto | 3 | 2.895 |
| 498 | open | 3 | 2.895 |
| 499 | opens | 3 | 2.895 |
| 500 | oxford | 3 | 2.895 |
| 501 | pain | 3 | 2.895 |
| 502 | paki | 3 | 2.895 |
| 503 | part | 3 | 2.895 |
| 504 | passed | 3 | 2.895 |
| 505 | period | 3 | 2.895 |
| 506 | picked | 3 | 2.895 |
| 507 | poetry | 3 | 2.895 |
| 508 | presence | 3 | 2.895 |
| 509 | pressed | 3 | 2.895 |
| 510 | prose | 3 | 2.895 |
| 511 | pushed | 3 | 2.895 |
| 512 | putting | 3 | 2.895 |
| 513 | rainy | 3 | 2.895 |
| 514 | remember | 3 | 2.895 |
| 515 | rerum | 3 | 2.895 |
| 516 | rest | 3 | 2.895 |
| 517 | returned | 3 | 2.895 |
| 518 | rima | 3 | 2.895 |
| 519 | rum | 3 | 2.895 |
| 520 | sailors | 3 | 2.895 |
| 521 | same | 3 | 2.895 |
| 522 | savannah | 3 | 2.895 |
| 523 | saying | 3 | 2.895 |
| 524 | scars | 3 | 2.895 |
| 525 | seascape | 3 | 2.895 |
| 526 | season | 3 | 2.895 |
| 527 | sexually | 3 | 2.895 |
| 528 | shame | 3 | 2.895 |
| 529 | shape | 3 | 2.895 |
| 530 | shock | 3 | 2.895 |
| 531 | sight | 3 | 2.895 |
| 532 | sign | 3 | 2.895 |
| 533 | since | 3 | 2.895 |
| 534 | sisters | 3 | 2.895 |
| 535 | slot | 3 | 2.895 |
| 536 | song | 3 | 2.895 |
| 537 | soon | 3 | 2.895 |
| 538 | spaces | 3 | 2.895 |
| 539 | special | 3 | 2.895 |
| 540 | status | 3 | 2.895 |
| 541 | stood | 3 | 2.895 |
| 542 | such | 3 | 2.895 |
| 543 | sunt | 3 | 2.895 |
| 544 | take | 3 | 2.895 |
| 545 | talk | 3 | 2.895 |
| 546 | teeth | 3 | 2.895 |
| 547 | thing | 3 | 2.895 |
| 548 | thirty | 3 | 2.895 |
| 549 | though | 3 | 2.895 |
| 550 | three | 3 | 2.895 |
| 551 | throughout | 3 | 2.895 |
| 552 | thy | 3 | 2.895 |
| 553 | top | 3 | 2.895 |
| 554 | tries | 3 | 2.895 |
| 555 | turn | 3 | 2.895 |
| 556 | turned | 3 | 2.895 |
| 557 | turns | 3 | 2.895 |
| 558 | universe | 3 | 2.895 |
| 559 | university | 3 | 2.895 |
| 560 | uttered | 3 | 2.895 |
| 561 | valleys | 3 | 2.895 |
| 562 | vast | 3 | 2.895 |
| 563 | voice | 3 | 2.895 |
| 564 | waited | 3 | 2.895 |
| 565 | waiting | 3 | 2.895 |
| 566 | wall | 3 | 2.895 |
| 567 | wanting | 3 | 2.895 |
| 568 | welcome | 3 | 2.895 |
| 569 | west | 3 | 2.895 |
| 570 | whom | 3 | 2.895 |
| 571 | word | 3 | 2.895 |
| 572 | world | 3 | 2.895 |
| 573 | writer | 3 | 2.895 |
| 574 | young | 3 | 2.895 |
| 575 | younger | 3 | 2.895 |
| 576 | a- | 2 | 1.930 |
| 577 | able | 2 | 1.930 |
| 578 | above | 2 | 1.930 |
| 579 | afraid | 2 | 1.930 |
| 580 | africans | 2 | 1.930 |
| 581 | also | 2 | 1.930 |
| 582 | amazon | 2 | 1.930 |
| 583 | anger | 2 | 1.930 |
| 584 | arms | 2 | 1.930 |
| 585 | aside | 2 | 1.930 |
| 586 | atlantic | 2 | 1.930 |
| 587 | authoritarian | 2 | 1.930 |
| 588 | authority | 2 | 1.930 |
| 589 | autobiographical | 2 | 1.930 |
| 590 | automatically | 2 | 1.930 |
| 591 | basest | 2 | 1.930 |
| 592 | beadless | 2 | 1.930 |
| 593 | beads | 2 | 1.930 |
| 594 | became | 2 | 1.930 |
| 595 | beckon | 2 | 1.930 |
| 596 | bed | 2 | 1.930 |
| 597 | believed | 2 | 1.930 |
| 598 | belly | 2 | 1.930 |
| 599 | beside | 2 | 1.930 |
| 600 | bewildered | 2 | 1.930 |
| 601 | birth | 2 | 1.930 |
| 602 | bit | 2 | 1.930 |
| 603 | blackness | 2 | 1.930 |
| 604 | blindly | 2 | 1.930 |
| 605 | blue | 2 | 1.930 |
| 606 | board | 2 | 1.930 |
| 607 | boldest | 2 | 1.930 |
| 608 | bone | 2 | 1.930 |
| 609 | booth | 2 | 1.930 |
| 610 | bottom | 2 | 1.930 |
| 611 | boundaries | 2 | 1.930 |
| 612 | bow | 2 | 1.930 |
| 613 | brilliant | 2 | 1.930 |
| 614 | brooding | 2 | 1.930 |
| 615 | brothers | 2 | 1.930 |
| 616 | bundle | 2 | 1.930 |
| 617 | bus | 2 | 1.930 |
| 618 | calf | 2 | 1.930 |
| 619 | care | 2 | 1.930 |
| 620 | centuries | 2 | 1.930 |
| 621 | certain | 2 | 1.930 |
| 622 | chap | 2 | 1.930 |
| 623 | cheeks | 2 | 1.930 |
| 624 | childbirth | 2 | 1.930 |
| 625 | children | 2 | 1.930 |
| 626 | cigarette | 2 | 1.930 |
| 627 | circus | 2 | 1.930 |
| 628 | class | 2 | 1.930 |
| 629 | clear | 2 | 1.930 |
| 630 | closes | 2 | 1.930 |
| 631 | coastal | 2 | 1.930 |
| 632 | coconuts | 2 | 1.930 |
| 633 | coin | 2 | 1.930 |
| 634 | cold | 2 | 1.930 |
| 635 | comes | 2 | 1.930 |
| 636 | commerce | 2 | 1.930 |
| 637 | community | 2 | 1.930 |
| 638 | constant | 2 | 1.930 |
| 639 | corn | 2 | 1.930 |
| 640 | corner | 2 | 1.930 |
| 641 | corners | 2 | 1.930 |
| 642 | couch | 2 | 1.930 |
| 643 | couple | 2 | 1.930 |
| 644 | courtly | 2 | 1.930 |
| 645 | crammed | 2 | 1.930 |
| 646 | crashing | 2 | 1.930 |
| 647 | creatures | 2 | 1.930 |
| 648 | cry | 2 | 1.930 |
| 649 | customers | 2 | 1.930 |
| 650 | dared | 2 | 1.930 |
| 651 | days | 2 | 1.930 |
| 652 | dazed | 2 | 1.930 |
| 653 | death | 2 | 1.930 |
| 654 | debased | 2 | 1.930 |
| 655 | deserving | 2 | 1.930 |
| 656 | desperate | 2 | 1.930 |
| 657 | died | 2 | 1.930 |
| 658 | direct | 2 | 1.930 |
| 659 | does | 2 | 1.930 |
| 660 | doesn't | 2 | 1.930 |
| 661 | doubts | 2 | 1.930 |
| 662 | drowning | 2 | 1.930 |
| 663 | drunk | 2 | 1.930 |
| 664 | dunciad | 2 | 1.930 |
| 665 | dust | 2 | 1.930 |
| 666 | easily | 2 | 1.930 |
| 667 | easy | 2 | 1.930 |
| 668 | edge | 2 | 1.930 |
| 669 | eh | 2 | 1.930 |
| 670 | elders | 2 | 1.930 |
| 671 | ends | 2 | 1.930 |
| 672 | equiano | 2 | 1.930 |
| 673 | eschatological | 2 | 1.930 |
| 674 | especially | 2 | 1.930 |
| 675 | eventually | 2 | 1.930 |
| 676 | ever | 2 | 1.930 |
| 677 | every | 2 | 1.930 |
| 678 | everything | 2 | 1.930 |
| 679 | exactly | 2 | 1.930 |
| 680 | existence | 2 | 1.930 |
| 681 | expecting | 2 | 1.930 |
| 682 | experience | 2 | 1.930 |
| 683 | external | 2 | 1.930 |
| 684 | faith | 2 | 1.930 |
| 685 | falls | 2 | 1.930 |
| 686 | far | 2 | 1.930 |
| 687 | fields | 2 | 1.930 |
| 688 | figure | 2 | 1.930 |
| 689 | find | 2 | 1.930 |
| 690 | flow | 2 | 1.930 |
| 691 | folds | 2 | 1.930 |
| 692 | foot | 2 | 1.930 |
| 693 | foreign | 2 | 1.930 |
| 694 | foretell | 2 | 1.930 |
| 695 | fortune | 2 | 1.930 |
| 696 | frantically | 2 | 1.930 |
| 697 | free | 2 | 1.930 |
| 698 | freedom | 2 | 1.930 |
| 699 | fright | 2 | 1.930 |
| 700 | fruit | 2 | 1.930 |
| 701 | g-, | 2 | 1.930 |
| 702 | gathered | 2 | 1.930 |
| 703 | genuine | 2 | 1.930 |
| 704 | ghosts | 2 | 1.930 |
| 705 | girl | 2 | 1.930 |
| 706 | girls | 2 | 1.930 |
| 707 | glass | 2 | 1.930 |
| 708 | goat | 2 | 1.930 |
| 709 | gown | 2 | 1.930 |
| 710 | grain | 2 | 1.930 |
| 711 | greeks | 2 | 1.930 |
| 712 | grew | 2 | 1.930 |
| 713 | grown | 2 | 1.930 |
| 714 | guilt | 2 | 1.930 |
| 715 | guyana's | 2 | 1.930 |
| 716 | half | 2 | 1.930 |
| 717 | hard | 2 | 1.930 |
| 718 | hate | 2 | 1.930 |
| 719 | held | 2 | 1.930 |
| 720 | herds | 2 | 1.930 |
| 721 | herself | 2 | 1.930 |
| 722 | hidden | 2 | 1.930 |
| 723 | hindu | 2 | 1.930 |
| 724 | holes | 2 | 1.930 |
| 725 | holocaust | 2 | 1.930 |
| 726 | hook | 2 | 1.930 |
| 727 | huge | 2 | 1.930 |
| 728 | human | 2 | 1.930 |
| 729 | humiliation | 2 | 1.930 |
| 730 | hundred-and- | 2 | 1.930 |
| 731 | hut | 2 | 1.930 |
| 732 | idiot | 2 | 1.930 |
| 733 | ignorant | 2 | 1.930 |
| 734 | image | 2 | 1.930 |
| 735 | impatient | 2 | 1.930 |
| 736 | important | 2 | 1.930 |
| 737 | impose | 2 | 1.930 |
| 738 | inherently | 2 | 1.930 |
| 739 | instructions | 2 | 1.930 |
| 740 | involved | 2 | 1.930 |
| 741 | joke | 2 | 1.930 |
| 742 | jouti | 2 | 1.930 |
| 743 | kaka's | 2 | 1.930 |
| 744 | keeps | 2 | 1.930 |
| 745 | key | 2 | 1.930 |
| 746 | kinds | 2 | 1.930 |
| 747 | knock | 2 | 1.930 |
| 748 | knowing | 2 | 1.930 |
| 749 | laid | 2 | 1.930 |
| 750 | later | 2 | 1.930 |
| 751 | leaned | 2 | 1.930 |
| 752 | leaving | 2 | 1.930 |
| 753 | levels | 2 | 1.930 |
| 754 | lights | 2 | 1.930 |
| 755 | lips | 2 | 1.930 |
| 756 | lives | 2 | 1.930 |
| 757 | logies | 2 | 1.930 |
| 758 | loss | 2 | 1.930 |
| 759 | lost | 2 | 1.930 |
| 760 | magazines | 2 | 1.930 |
| 761 | magicians | 2 | 1.930 |
| 762 | making | 2 | 1.930 |
| 763 | mangoes | 2 | 1.930 |
| 764 | manu's | 2 | 1.930 |
| 765 | martin | 2 | 1.930 |
| 766 | marvelling | 2 | 1.930 |
| 767 | middle | 2 | 1.930 |
| 768 | migrate | 2 | 1.930 |
| 769 | mocking | 2 | 1.930 |
| 770 | moment | 2 | 1.930 |
| 771 | momentum | 2 | 1.930 |
| 772 | monotonously | 2 | 1.930 |
| 773 | months | 2 | 1.930 |
| 774 | morning | 2 | 1.930 |
| 775 | mortar | 2 | 1.930 |
| 776 | mouths | 2 | 1.930 |
| 777 | moved | 2 | 1.930 |
| 778 | mud | 2 | 1.930 |
| 779 | muddy | 2 | 1.930 |
| 780 | mythology | 2 | 1.930 |
| 781 | nameless | 2 | 1.930 |
| 782 | naming | 2 | 1.930 |
| 783 | nature | 2 | 1.930 |
| 784 | neither | 2 | 1.930 |
| 785 | neuroses | 2 | 1.930 |
| 786 | next | 2 | 1.930 |
| 787 | nineteen | 2 | 1.930 |
| 788 | noise | 2 | 1.930 |
| 789 | nose | 2 | 1.930 |
| 790 | odd | 2 | 1.930 |
| 791 | often | 2 | 1.930 |
| 792 | oh | 2 | 1.930 |
| 793 | ornamental | 2 | 1.930 |
| 794 | others | 2 | 1.930 |
| 795 | page | 2 | 1.930 |
| 796 | passionate | 2 | 1.930 |
| 797 | past | 2 | 1.930 |
| 798 | paths | 2 | 1.930 |
| 799 | pavement | 2 | 1.930 |
| 800 | pay | 2 | 1.930 |
| 801 | peculiar | 2 | 1.930 |
| 802 | peepshow | 2 | 1.930 |
| 803 | pence | 2 | 1.930 |
| 804 | perilous | 2 | 1.930 |
| 805 | perish | 2 | 1.930 |
| 806 | piccadilly | 2 | 1.930 |
| 807 | pictures | 2 | 1.930 |
| 808 | pincher | 2 | 1.930 |
| 809 | places | 2 | 1.930 |
| 810 | plague | 2 | 1.930 |
| 811 | plane | 2 | 1.930 |
| 812 | pleasure | 2 | 1.930 |
| 813 | 2 | 1.930 | |
| 814 | pool | 2 | 1.930 |
| 815 | poor | 2 | 1.930 |
| 816 | possibility | 2 | 1.930 |
| 817 | previous | 2 | 1.930 |
| 818 | pride | 2 | 1.930 |
| 819 | promised | 2 | 1.930 |
| 820 | protection | 2 | 1.930 |
| 821 | pure | 2 | 1.930 |
| 822 | purse | 2 | 1.930 |
| 823 | quick | 2 | 1.930 |
| 824 | rack | 2 | 1.930 |
| 825 | rain | 2 | 1.930 |
| 826 | rainforest | 2 | 1.930 |
| 827 | raw | 2 | 1.930 |
| 828 | re-, | 2 | 1.930 |
| 829 | recognize | 2 | 1.930 |
| 830 | relationship | 2 | 1.930 |
| 831 | relax | 2 | 1.930 |
| 832 | remains | 2 | 1.930 |
| 833 | response | 2 | 1.930 |
| 834 | river | 2 | 1.930 |
| 835 | romance | 2 | 1.930 |
| 836 | round | 2 | 1.930 |
| 837 | rubbish | 2 | 1.930 |
| 838 | rudeness | 2 | 1.930 |
| 839 | sake | 2 | 1.930 |
| 840 | salt | 2 | 1.930 |
| 841 | school | 2 | 1.930 |
| 842 | scunt | 2 | 1.930 |
| 843 | search | 2 | 1.930 |
| 844 | searched | 2 | 1.930 |
| 845 | secret | 2 | 1.930 |
| 846 | secretly | 2 | 1.930 |
| 847 | secure | 2 | 1.930 |
| 848 | seemed | 2 | 1.930 |
| 849 | seeps | 2 | 1.930 |
| 850 | self | 2 | 1.930 |
| 851 | setting | 2 | 1.930 |
| 852 | settled | 2 | 1.930 |
| 853 | seven-and-a-half-thousand | 2 | 1.930 |
| 854 | shah's | 2 | 1.930 |
| 855 | she's | 2 | 1.930 |
| 856 | shores | 2 | 1.930 |
| 857 | show | 2 | 1.930 |
| 858 | shyness | 2 | 1.930 |
| 859 | silver | 2 | 1.930 |
| 860 | sits | 2 | 1.930 |
| 861 | slap | 2 | 1.930 |
| 862 | sleep | 2 | 1.930 |
| 863 | sought | 2 | 1.930 |
| 864 | sound | 2 | 1.930 |
| 865 | stare | 2 | 1.930 |
| 866 | stared | 2 | 1.930 |
| 867 | staring | 2 | 1.930 |
| 868 | stayed | 2 | 1.930 |
| 869 | steal | 2 | 1.930 |
| 870 | steel | 2 | 1.930 |
| 871 | strange | 2 | 1.930 |
| 872 | street | 2 | 1.930 |
| 873 | strip | 2 | 1.930 |
| 874 | struggle | 2 | 1.930 |
| 875 | sublime | 2 | 1.930 |
| 876 | suddenly | 2 | 1.930 |
| 877 | suggest | 2 | 1.930 |
| 878 | sunk | 2 | 1.930 |
| 879 | sure | 2 | 1.930 |
| 880 | swum | 2 | 1.930 |
| 881 | tabla | 2 | 1.930 |
| 882 | taken | 2 | 1.930 |
| 883 | talking | 2 | 1.930 |
| 884 | talks | 2 | 1.930 |
| 885 | tanda's | 2 | 1.930 |
| 886 | tax | 2 | 1.930 |
| 887 | tea | 2 | 1.930 |
| 888 | teach | 2 | 1.930 |
| 889 | tempts | 2 | 1.930 |
| 890 | ten | 2 | 1.930 |
| 891 | terrified | 2 | 1.930 |
| 892 | thomas | 2 | 1.930 |
| 893 | throwing | 2 | 1.930 |
| 894 | thrown | 2 | 1.930 |
| 895 | tilt | 2 | 1.930 |
| 896 | tongue | 2 | 1.930 |
| 897 | toys | 2 | 1.930 |
| 898 | trail | 2 | 1.930 |
| 899 | trance | 2 | 1.930 |
| 900 | transformed | 2 | 1.930 |
| 901 | treasures | 2 | 1.930 |
| 902 | trees | 2 | 1.930 |
| 903 | tribes | 2 | 1.930 |
| 904 | tropical | 2 | 1.930 |
| 905 | under | 2 | 1.930 |
| 906 | unstable | 2 | 1.930 |
| 907 | urged | 2 | 1.930 |
| 908 | urns | 2 | 1.930 |
| 909 | v-, | 2 | 1.930 |
| 910 | voices | 2 | 1.930 |
| 911 | vulgar | 2 | 1.930 |
| 912 | walcott | 2 | 1.930 |
| 913 | walk | 2 | 1.930 |
| 914 | walked | 2 | 1.930 |
| 915 | warming | 2 | 1.930 |
| 916 | watching | 2 | 1.930 |
| 917 | wear | 2 | 1.930 |
| 918 | while | 2 | 1.930 |
| 919 | whilst | 2 | 1.930 |
| 920 | whisper | 2 | 1.930 |
| 921 | whispered | 2 | 1.930 |
| 922 | wind | 2 | 1.930 |
| 923 | window | 2 | 1.930 |
| 924 | wisdom | 2 | 1.930 |
| 925 | wood | 2 | 1.930 |
| 926 | worms | 2 | 1.930 |
| 927 | wounds | 2 | 1.930 |
| 928 | y-, | 2 | 1.930 |
| 929 | you'll | 2 | 1.930 |
| 930 | you've | 2 | 1.930 |
| 931 | a-, | 1 | 0.965 |
| 932 | a-n-a-r-c-h | 1 | 0.965 |
| 933 | aboard | 1 | 0.965 |
| 934 | abolition | 1 | 0.965 |
| 935 | abor-, | 1 | 0.965 |
| 936 | aborigines | 1 | 0.965 |
| 937 | aborted | 1 | 0.965 |
| 938 | abscond | 1 | 0.965 |
| 939 | absent | 1 | 0.965 |
| 940 | absolutely | 1 | 0.965 |
| 941 | acceptable | 1 | 0.965 |
| 942 | accepted | 1 | 0.965 |
| 943 | accustomed | 1 | 0.965 |
| 944 | acha | 1 | 0.965 |
| 945 | aching | 1 | 0.965 |
| 946 | acknowledged | 1 | 0.965 |
| 947 | acquired | 1 | 0.965 |
| 948 | adjoining | 1 | 0.965 |
| 949 | admiration | 1 | 0.965 |
| 950 | admire | 1 | 0.965 |
| 951 | admired | 1 | 0.965 |
| 952 | admixture | 1 | 0.965 |
| 953 | adorned | 1 | 0.965 |
| 954 | adv-, | 1 | 0.965 |
| 955 | advance | 1 | 0.965 |
| 956 | affect | 1 | 0.965 |
| 957 | age | 1 | 0.965 |
| 958 | agitated | 1 | 0.965 |
| 959 | agreement | 1 | 0.965 |
| 960 | ahead | 1 | 0.965 |
| 961 | ain't | 1 | 0.965 |
| 962 | alarm | 1 | 0.965 |
| 963 | already | 1 | 0.965 |
| 964 | although | 1 | 0.965 |
| 965 | ambiguity | 1 | 0.965 |
| 966 | ambushes | 1 | 0.965 |
| 967 | amen | 1 | 0.965 |
| 968 | amerindian | 1 | 0.965 |
| 969 | amerindians | 1 | 0.965 |
| 970 | amusement | 1 | 0.965 |
| 971 | ancestral | 1 | 0.965 |
| 972 | anchored | 1 | 0.965 |
| 973 | ancient | 1 | 0.965 |
| 974 | anew | 1 | 0.965 |
| 975 | angel | 1 | 0.965 |
| 976 | angelic | 1 | 0.965 |
| 977 | anglican | 1 | 0.965 |
| 978 | anguish | 1 | 0.965 |
| 979 | anniversary | 1 | 0.965 |
| 980 | announces | 1 | 0.965 |
| 981 | answer | 1 | 0.965 |
| 982 | antique | 1 | 0.965 |
| 983 | antisocial | 1 | 0.965 |
| 984 | anything | 1 | 0.965 |
| 985 | anywhere | 1 | 0.965 |
| 986 | ap-, | 1 | 0.965 |
| 987 | apologies | 1 | 0.965 |
| 988 | apologist | 1 | 0.965 |
| 989 | apologize | 1 | 0.965 |
| 990 | appear | 1 | 0.965 |
| 991 | appearance | 1 | 0.965 |
| 992 | appease | 1 | 0.965 |
| 993 | arbitrary | 1 | 0.965 |
| 994 | arcades | 1 | 0.965 |
| 995 | aristotle | 1 | 0.965 |
| 996 | arose | 1 | 0.965 |
| 997 | arrange | 1 | 0.965 |
| 998 | arrived | 1 | 0.965 |
| 999 | arrogance | 1 | 0.965 |
| 1000 | arrow | 1 | 0.965 |
| 1001 | article | 1 | 0.965 |
| 1002 | artifice | 1 | 0.965 |
| 1003 | as-, | 1 | 0.965 |
| 1004 | aspects | 1 | 0.965 |
| 1005 | assault | 1 | 0.965 |
| 1006 | assigned | 1 | 0.965 |
| 1007 | assumed | 1 | 0.965 |
| 1008 | astonished | 1 | 0.965 |
| 1009 | await | 1 | 0.965 |
| 1010 | awaken | 1 | 0.965 |
| 1011 | awakens | 1 | 0.965 |
| 1012 | awed | 1 | 0.965 |
| 1013 | awhile | 1 | 0.965 |
| 1014 | awoke | 1 | 0.965 |
| 1015 | babbled | 1 | 0.965 |
| 1016 | babbling | 1 | 0.965 |
| 1017 | babies | 1 | 0.965 |
| 1018 | backdam | 1 | 0.965 |
| 1019 | backsides | 1 | 0.965 |
| 1020 | backwards | 1 | 0.965 |
| 1021 | bags | 1 | 0.965 |
| 1022 | baju's | 1 | 0.965 |
| 1023 | baked | 1 | 0.965 |
| 1024 | banged | 1 | 0.965 |
| 1025 | bank | 1 | 0.965 |
| 1026 | barely | 1 | 0.965 |
| 1027 | barred | 1 | 0.965 |
| 1028 | barrels | 1 | 0.965 |
| 1029 | barren | 1 | 0.965 |
| 1030 | base | 1 | 0.965 |
| 1031 | based | 1 | 0.965 |
| 1032 | basis | 1 | 0.965 |
| 1033 | bastards | 1 | 0.965 |
| 1034 | bathos | 1 | 0.965 |
| 1035 | battleground | 1 | 0.965 |
| 1036 | bawling | 1 | 0.965 |
| 1037 | bear | 1 | 0.965 |
| 1038 | beasts | 1 | 0.965 |
| 1039 | beaten | 1 | 0.965 |
| 1040 | beforehand | 1 | 0.965 |
| 1041 | beggar | 1 | 0.965 |
| 1042 | beggared | 1 | 0.965 |
| 1043 | begging | 1 | 0.965 |
| 1044 | beginning | 1 | 0.965 |
| 1045 | beguiled | 1 | 0.965 |
| 1046 | beholds | 1 | 0.965 |
| 1047 | bellies | 1 | 0.965 |
| 1048 | belonged | 1 | 0.965 |
| 1049 | beloved | 1 | 0.965 |
| 1050 | bench | 1 | 0.965 |
| 1051 | bends | 1 | 0.965 |
| 1052 | beneath | 1 | 0.965 |
| 1053 | bereft | 1 | 0.965 |
| 1054 | beseech | 1 | 0.965 |
| 1055 | bespeak | 1 | 0.965 |
| 1056 | best | 1 | 0.965 |
| 1057 | betoken | 1 | 0.965 |
| 1058 | betrayal | 1 | 0.965 |
| 1059 | betrayed | 1 | 0.965 |
| 1060 | betrayer | 1 | 0.965 |
| 1061 | better | 1 | 0.965 |
| 1062 | billboards | 1 | 0.965 |
| 1063 | bitch | 1 | 0.965 |
| 1064 | bites | 1 | 0.965 |
| 1065 | bits | 1 | 0.965 |
| 1066 | bizarre | 1 | 0.965 |
| 1067 | bla-, | 1 | 0.965 |
| 1068 | blacker | 1 | 0.965 |
| 1069 | blade | 1 | 0.965 |
| 1070 | blasted | 1 | 0.965 |
| 1071 | bleakly | 1 | 0.965 |
| 1072 | blessed | 1 | 0.965 |
| 1073 | blindfolds | 1 | 0.965 |
| 1074 | blinds | 1 | 0.965 |
| 1075 | blood-cloth | 1 | 0.965 |
| 1076 | blossoming | 1 | 0.965 |
| 1077 | blow | 1 | 0.965 |
| 1078 | blowing | 1 | 0.965 |
| 1079 | blurb | 1 | 0.965 |
| 1080 | boiled | 1 | 0.965 |
| 1081 | boils | 1 | 0.965 |
| 1082 | bore | 1 | 0.965 |
| 1083 | bosom | 1 | 0.965 |
| 1084 | both | 1 | 0.965 |
| 1085 | bourg-, | 1 | 0.965 |
| 1086 | bourgeoisie | 1 | 0.965 |
| 1087 | bowl | 1 | 0.965 |
| 1088 | box | 1 | 0.965 |
| 1089 | boys' | 1 | 0.965 |
| 1090 | braced | 1 | 0.965 |
| 1091 | breakfast | 1 | 0.965 |
| 1092 | breaks | 1 | 0.965 |
| 1093 | breast | 1 | 0.965 |
| 1094 | breasts | 1 | 0.965 |
| 1095 | breathless | 1 | 0.965 |
| 1096 | breeding | 1 | 0.965 |
| 1097 | brick | 1 | 0.965 |
| 1098 | brides | 1 | 0.965 |
| 1099 | briefly | 1 | 0.965 |
| 1100 | brings | 1 | 0.965 |
| 1101 | bro-, | 1 | 0.965 |
| 1102 | broad | 1 | 0.965 |
| 1103 | brought | 1 | 0.965 |
| 1104 | bruise | 1 | 0.965 |
| 1105 | bruised | 1 | 0.965 |
| 1106 | bruises | 1 | 0.965 |
| 1107 | bruising | 1 | 0.965 |
| 1108 | bubbling | 1 | 0.965 |
| 1109 | bugger | 1 | 0.965 |
| 1110 | buoying | 1 | 0.965 |
| 1111 | burden | 1 | 0.965 |
| 1112 | burial | 1 | 0.965 |
| 1113 | buries | 1 | 0.965 |
| 1114 | burning | 1 | 0.965 |
| 1115 | buy | 1 | 0.965 |
| 1116 | c-s | 1 | 0.965 |
| 1117 | cackled | 1 | 0.965 |
| 1118 | cakes | 1 | 0.965 |
| 1119 | calculating | 1 | 0.965 |
| 1120 | calling | 1 | 0.965 |
| 1121 | canals | 1 | 0.965 |
| 1122 | canefields | 1 | 0.965 |
| 1123 | cannon | 1 | 0.965 |
| 1124 | cannot | 1 | 0.965 |
| 1125 | canonical | 1 | 0.965 |
| 1126 | canyons | 1 | 0.965 |
| 1127 | capitalizing | 1 | 0.965 |
| 1128 | captain's | 1 | 0.965 |
| 1129 | careful | 1 | 0.965 |
| 1130 | caressed | 1 | 0.965 |
| 1131 | cargo | 1 | 0.965 |
| 1132 | carnival | 1 | 0.965 |
| 1133 | carve | 1 | 0.965 |
| 1134 | carved | 1 | 0.965 |
| 1135 | cast | 1 | 0.965 |
| 1136 | catching | 1 | 0.965 |
| 1137 | caused | 1 | 0.965 |
| 1138 | ceremonies | 1 | 0.965 |
| 1139 | chained | 1 | 0.965 |
| 1140 | chains | 1 | 0.965 |
| 1141 | chants | 1 | 0.965 |
| 1142 | chapter | 1 | 0.965 |
| 1143 | character | 1 | 0.965 |
| 1144 | chasing | 1 | 0.965 |
| 1145 | chaucer | 1 | 0.965 |
| 1146 | chaucer's | 1 | 0.965 |
| 1147 | cheap | 1 | 0.965 |
| 1148 | checked | 1 | 0.965 |
| 1149 | checks | 1 | 0.965 |
| 1150 | cheque | 1 | 0.965 |
| 1151 | cherubims | 1 | 0.965 |
| 1152 | chests | 1 | 0.965 |
| 1153 | chisel | 1 | 0.965 |
| 1154 | choice | 1 | 0.965 |
| 1155 | choose | 1 | 0.965 |
| 1156 | christian | 1 | 0.965 |
| 1157 | chronicles | 1 | 0.965 |
| 1158 | chuck | 1 | 0.965 |
| 1159 | church | 1 | 0.965 |
| 1160 | cinemas | 1 | 0.965 |
| 1161 | circumference | 1 | 0.965 |
| 1162 | civilization | 1 | 0.965 |
| 1163 | clasped | 1 | 0.965 |
| 1164 | clean | 1 | 0.965 |
| 1165 | clearly | 1 | 0.965 |
| 1166 | clears | 1 | 0.965 |
| 1167 | cleeps | 1 | 0.965 |
| 1168 | clenched | 1 | 0.965 |
| 1169 | climax | 1 | 0.965 |
| 1170 | climbing | 1 | 0.965 |
| 1171 | clogged | 1 | 0.965 |
| 1172 | cloth | 1 | 0.965 |
| 1173 | clothes | 1 | 0.965 |
| 1174 | cloudless | 1 | 0.965 |
| 1175 | clouds | 1 | 0.965 |
| 1176 | clowns | 1 | 0.965 |
| 1177 | coarse | 1 | 0.965 |
| 1178 | coarsely | 1 | 0.965 |
| 1179 | coast | 1 | 0.965 |
| 1180 | coastline | 1 | 0.965 |
| 1181 | coax | 1 | 0.965 |
| 1182 | cobs | 1 | 0.965 |
| 1183 | cocaine | 1 | 0.965 |
| 1184 | collapse | 1 | 0.965 |
| 1185 | collide | 1 | 0.965 |
| 1186 | colonies | 1 | 0.965 |
| 1187 | colonize | 1 | 0.965 |
| 1188 | columbus | 1 | 0.965 |
| 1189 | comedy | 1 | 0.965 |
| 1190 | comely | 1 | 0.965 |
| 1191 | command | 1 | 0.965 |
| 1192 | commer-, | 1 | 0.965 |
| 1193 | common | 1 | 0.965 |
| 1194 | compassion | 1 | 0.965 |
| 1195 | complete | 1 | 0.965 |
| 1196 | composed | 1 | 0.965 |
| 1197 | compound | 1 | 0.965 |
| 1198 | concealing | 1 | 0.965 |
| 1199 | concentration | 1 | 0.965 |
| 1200 | concerned | 1 | 0.965 |
| 1201 | conclusion | 1 | 0.965 |
| 1202 | conference | 1 | 0.965 |
| 1203 | confidently | 1 | 0.965 |
| 1204 | confront | 1 | 0.965 |
| 1205 | confronting | 1 | 0.965 |
| 1206 | confuses | 1 | 0.965 |
| 1207 | congealed | 1 | 0.965 |
| 1208 | conjures | 1 | 0.965 |
| 1209 | connect | 1 | 0.965 |
| 1210 | connection | 1 | 0.965 |
| 1211 | conquistador | 1 | 0.965 |
| 1212 | consciousness | 1 | 0.965 |
| 1213 | consideration | 1 | 0.965 |
| 1214 | considering | 1 | 0.965 |
| 1215 | conspiracy | 1 | 0.965 |
| 1216 | content | 1 | 0.965 |
| 1217 | context | 1 | 0.965 |
| 1218 | continues | 1 | 0.965 |
| 1219 | convinced | 1 | 0.965 |
| 1220 | coolies | 1 | 0.965 |
| 1221 | coral | 1 | 0.965 |
| 1222 | core | 1 | 0.965 |
| 1223 | cork | 1 | 0.965 |
| 1224 | corpse | 1 | 0.965 |
| 1225 | cosmos | 1 | 0.965 |
| 1226 | cougars | 1 | 0.965 |
| 1227 | count | 1 | 0.965 |
| 1228 | counted | 1 | 0.965 |
| 1229 | counterfeit | 1 | 0.965 |
| 1230 | country | 1 | 0.965 |
| 1231 | courtship | 1 | 0.965 |
| 1232 | cousin | 1 | 0.965 |
| 1233 | cover | 1 | 0.965 |
| 1234 | cowardice | 1 | 0.965 |
| 1235 | cowrie | 1 | 0.965 |
| 1236 | cows | 1 | 0.965 |
| 1237 | crab-back | 1 | 0.965 |
| 1238 | crazy | 1 | 0.965 |
| 1239 | creased | 1 | 0.965 |
| 1240 | created | 1 | 0.965 |
| 1241 | creates | 1 | 0.965 |
| 1242 | creating | 1 | 0.965 |
| 1243 | creature | 1 | 0.965 |
| 1244 | creolization | 1 | 0.965 |
| 1245 | crest | 1 | 0.965 |
| 1246 | crevices | 1 | 0.965 |
| 1247 | cried | 1 | 0.965 |
| 1248 | crimson | 1 | 0.965 |
| 1249 | criseyde's | 1 | 0.965 |
| 1250 | criteria | 1 | 0.965 |
| 1251 | critic | 1 | 0.965 |
| 1252 | critical | 1 | 0.965 |
| 1253 | crop | 1 | 0.965 |
| 1254 | cross-legged | 1 | 0.965 |
| 1255 | crossed | 1 | 0.965 |
| 1256 | crowd | 1 | 0.965 |
| 1257 | crucifixes | 1 | 0.965 |
| 1258 | crudest | 1 | 0.965 |
| 1259 | crumbling | 1 | 0.965 |
| 1260 | cubla | 1 | 0.965 |
| 1261 | cuff | 1 | 0.965 |
| 1262 | cultural | 1 | 0.965 |
| 1263 | cunning | 1 | 0.965 |
| 1264 | cunt | 1 | 0.965 |
| 1265 | cunt-doll | 1 | 0.965 |
| 1266 | cup | 1 | 0.965 |
| 1267 | curls | 1 | 0.965 |
| 1268 | currents | 1 | 0.965 |
| 1269 | curry | 1 | 0.965 |
| 1270 | curson | 1 | 0.965 |
| 1271 | curves | 1 | 0.965 |
| 1272 | cut | 1 | 0.965 |
| 1273 | d-phil | 1 | 0.965 |
| 1274 | dams | 1 | 0.965 |
| 1275 | daniel | 1 | 0.965 |
| 1276 | dark | 1 | 0.965 |
| 1277 | dart | 1 | 0.965 |
| 1278 | dawn | 1 | 0.965 |
| 1279 | day's | 1 | 0.965 |
| 1280 | dazzle | 1 | 0.965 |
| 1281 | debauchery | 1 | 0.965 |
| 1282 | debt | 1 | 0.965 |
| 1283 | decipher | 1 | 0.965 |
| 1284 | decorative | 1 | 0.965 |
| 1285 | deed | 1 | 0.965 |
| 1286 | deeds | 1 | 0.965 |
| 1287 | defensive | 1 | 0.965 |
| 1288 | defined | 1 | 0.965 |
| 1289 | defining | 1 | 0.965 |
| 1290 | definite | 1 | 0.965 |
| 1291 | defoe | 1 | 0.965 |
| 1292 | defoe's | 1 | 0.965 |
| 1293 | degradation | 1 | 0.965 |
| 1294 | degrees | 1 | 0.965 |
| 1295 | deliberately | 1 | 0.965 |
| 1296 | delivered | 1 | 0.965 |
| 1297 | demons | 1 | 0.965 |
| 1298 | deny | 1 | 0.965 |
| 1299 | depths | 1 | 0.965 |
| 1300 | descriptions | 1 | 0.965 |
| 1301 | deserve | 1 | 0.965 |
| 1302 | design | 1 | 0.965 |
| 1303 | destination | 1 | 0.965 |
| 1304 | destroy | 1 | 0.965 |
| 1305 | detects | 1 | 0.965 |
| 1306 | devices | 1 | 0.965 |
| 1307 | devoted | 1 | 0.965 |
| 1308 | devotion | 1 | 0.965 |
| 1309 | diamond | 1 | 0.965 |
| 1310 | diet | 1 | 0.965 |
| 1311 | digging | 1 | 0.965 |
| 1312 | diminished | 1 | 0.965 |
| 1313 | diomede's | 1 | 0.965 |
| 1314 | dips | 1 | 0.965 |
| 1315 | directly | 1 | 0.965 |
| 1316 | dirt | 1 | 0.965 |
| 1317 | dirty | 1 | 0.965 |
| 1318 | disappear | 1 | 0.965 |
| 1319 | disappeared | 1 | 0.965 |
| 1320 | disappears | 1 | 0.965 |
| 1321 | discernible | 1 | 0.965 |
| 1322 | dishevelled | 1 | 0.965 |
| 1323 | disperse | 1 | 0.965 |
| 1324 | display | 1 | 0.965 |
| 1325 | dissertation | 1 | 0.965 |
| 1326 | dissolve | 1 | 0.965 |
| 1327 | divided | 1 | 0.965 |
| 1328 | done | 1 | 0.965 |
| 1329 | door | 1 | 0.965 |
| 1330 | doorways | 1 | 0.965 |
| 1331 | dough | 1 | 0.965 |
| 1332 | douse | 1 | 0.965 |
| 1333 | dozen | 1 | 0.965 |
| 1334 | drank | 1 | 0.965 |
| 1335 | dread | 1 | 0.965 |
| 1336 | dreadful | 1 | 0.965 |
| 1337 | dream | 1 | 0.965 |
| 1338 | dreamed | 1 | 0.965 |
| 1339 | dregs | 1 | 0.965 |
| 1340 | dress | 1 | 0.965 |
| 1341 | drew | 1 | 0.965 |
| 1342 | drifting | 1 | 0.965 |
| 1343 | drink | 1 | 0.965 |
| 1344 | drives | 1 | 0.965 |
| 1345 | dropped | 1 | 0.965 |
| 1346 | droppings | 1 | 0.965 |
| 1347 | dug | 1 | 0.965 |
| 1348 | dull | 1 | 0.965 |
| 1349 | dumping | 1 | 0.965 |
| 1350 | dung | 1 | 0.965 |
| 1351 | during | 1 | 0.965 |
| 1352 | dutifully | 1 | 0.965 |
| 1353 | dying | 1 | 0.965 |
| 1354 | e-, | 1 | 0.965 |
| 1355 | earlier | 1 | 0.965 |
| 1356 | ease | 1 | 0.965 |
| 1357 | easier | 1 | 0.965 |
| 1358 | eaten | 1 | 0.965 |
| 1359 | ecstatic | 1 | 0.965 |
| 1360 | edit | 1 | 0.965 |
| 1361 | eggs | 1 | 0.965 |
| 1362 | eight | 1 | 0.965 |
| 1363 | eighteen | 1 | 0.965 |
| 1364 | eighteen- | 1 | 0.965 |
| 1365 | either | 1 | 0.965 |
| 1366 | elapsed | 1 | 0.965 |
| 1367 | electronic | 1 | 0.965 |
| 1368 | eloquently | 1 | 0.965 |
| 1369 | else | 1 | 0.965 |
| 1370 | emerges | 1 | 0.965 |
| 1371 | empire | 1 | 0.965 |
| 1372 | emptiness | 1 | 0.965 |
| 1373 | endless | 1 | 0.965 |
| 1374 | endow | 1 | 0.965 |
| 1375 | endowed | 1 | 0.965 |
| 1376 | enfolding | 1 | 0.965 |
| 1377 | engrossed | 1 | 0.965 |
| 1378 | enrich | 1 | 0.965 |
| 1379 | enslaved | 1 | 0.965 |
| 1380 | entrance | 1 | 0.965 |
| 1381 | entreaties | 1 | 0.965 |
| 1382 | epic | 1 | 0.965 |
| 1383 | epistemological | 1 | 0.965 |
| 1384 | equal | 1 | 0.965 |
| 1385 | eradication | 1 | 0.965 |
| 1386 | erases | 1 | 0.965 |
| 1387 | escarpments | 1 | 0.965 |
| 1388 | eskimos | 1 | 0.965 |
| 1389 | essay | 1 | 0.965 |
| 1390 | evening | 1 | 0.965 |
| 1391 | everybody | 1 | 0.965 |
| 1392 | evil | 1 | 0.965 |
| 1393 | evoke | 1 | 0.965 |
| 1394 | ex-student | 1 | 0.965 |
| 1395 | examination | 1 | 0.965 |
| 1396 | examine | 1 | 0.965 |
| 1397 | examined | 1 | 0.965 |
| 1398 | examining | 1 | 0.965 |
| 1399 | exchanges | 1 | 0.965 |
| 1400 | excitement | 1 | 0.965 |
| 1401 | exercised | 1 | 0.965 |
| 1402 | exhaustion | 1 | 0.965 |
| 1403 | exotic | 1 | 0.965 |
| 1404 | explores | 1 | 0.965 |
| 1405 | exploring | 1 | 0.965 |
| 1406 | exposed | 1 | 0.965 |
| 1407 | extravagant | 1 | 0.965 |
| 1408 | failed | 1 | 0.965 |
| 1409 | faithful | 1 | 0.965 |
| 1410 | falling | 1 | 0.965 |
| 1411 | familiar | 1 | 0.965 |
| 1412 | familiarity | 1 | 0.965 |
| 1413 | fanned | 1 | 0.965 |
| 1414 | fanning | 1 | 0.965 |
| 1415 | fantastic | 1 | 0.965 |
| 1416 | fare | 1 | 0.965 |
| 1417 | fascist | 1 | 0.965 |
| 1418 | fashion | 1 | 0.965 |
| 1419 | fate | 1 | 0.965 |
| 1420 | fatten | 1 | 0.965 |
| 1421 | fattening | 1 | 0.965 |
| 1422 | favour | 1 | 0.965 |
| 1423 | favourite | 1 | 0.965 |
| 1424 | favours | 1 | 0.965 |
| 1425 | fearful | 1 | 0.965 |
| 1426 | feel | 1 | 0.965 |
| 1427 | feign | 1 | 0.965 |
| 1428 | fell | 1 | 0.965 |
| 1429 | fence | 1 | 0.965 |
| 1430 | fidgeting | 1 | 0.965 |
| 1431 | field | 1 | 0.965 |
| 1432 | fiercely | 1 | 0.965 |
| 1433 | fifteen-thousand | 1 | 0.965 |
| 1434 | fifty-thousand-million | 1 | 0.965 |
| 1435 | file | 1 | 0.965 |
| 1436 | filled | 1 | 0.965 |
| 1437 | filling | 1 | 0.965 |
| 1438 | film | 1 | 0.965 |
| 1439 | filter | 1 | 0.965 |
| 1440 | fine | 1 | 0.965 |
| 1441 | fingers | 1 | 0.965 |
| 1442 | finish | 1 | 0.965 |
| 1443 | finished | 1 | 0.965 |
| 1444 | fireside | 1 | 0.965 |
| 1445 | fished | 1 | 0.965 |
| 1446 | fist | 1 | 0.965 |
| 1447 | fit | 1 | 0.965 |
| 1448 | five-hundredth | 1 | 0.965 |
| 1449 | flames | 1 | 0.965 |
| 1450 | flashed | 1 | 0.965 |
| 1451 | flat | 1 | 0.965 |
| 1452 | flayed | 1 | 0.965 |
| 1453 | flecks | 1 | 0.965 |
| 1454 | flicked | 1 | 0.965 |
| 1455 | flicking | 1 | 0.965 |
| 1456 | flies | 1 | 0.965 |
| 1457 | float | 1 | 0.965 |
| 1458 | flood | 1 | 0.965 |
| 1459 | flooding | 1 | 0.965 |
| 1460 | flowers | 1 | 0.965 |
| 1461 | flowers' | 1 | 0.965 |
| 1462 | flush | 1 | 0.965 |
| 1463 | fly | 1 | 0.965 |
| 1464 | foil | 1 | 0.965 |
| 1465 | foliage | 1 | 0.965 |
| 1466 | followed | 1 | 0.965 |
| 1467 | fondled | 1 | 0.965 |
| 1468 | food | 1 | 0.965 |
| 1469 | footstep | 1 | 0.965 |
| 1470 | forbidden | 1 | 0.965 |
| 1471 | force | 1 | 0.965 |
| 1472 | foreground | 1 | 0.965 |
| 1473 | forehead | 1 | 0.965 |
| 1474 | forget | 1 | 0.965 |
| 1475 | forgive | 1 | 0.965 |
| 1476 | forgot | 1 | 0.965 |
| 1477 | forgotten | 1 | 0.965 |
| 1478 | forlornly | 1 | 0.965 |
| 1479 | forms | 1 | 0.965 |
| 1480 | forth | 1 | 0.965 |
| 1481 | fortifications | 1 | 0.965 |
| 1482 | fountain | 1 | 0.965 |
| 1483 | fountaining | 1 | 0.965 |
| 1484 | fours | 1 | 0.965 |
| 1485 | frail | 1 | 0.965 |
| 1486 | frangipani | 1 | 0.965 |
| 1487 | freshly | 1 | 0.965 |
| 1488 | freshness | 1 | 0.965 |
| 1489 | fried | 1 | 0.965 |
| 1490 | friends | 1 | 0.965 |
| 1491 | frig-, | 1 | 0.965 |
| 1492 | frigates | 1 | 0.965 |
| 1493 | frigged | 1 | 0.965 |
| 1494 | front | 1 | 0.965 |
| 1495 | froze | 1 | 0.965 |
| 1496 | fuck-arse | 1 | 0.965 |
| 1497 | fumbled | 1 | 0.965 |
| 1498 | further | 1 | 0.965 |
| 1499 | gaiety | 1 | 0.965 |
| 1500 | game | 1 | 0.965 |
| 1501 | gang | 1 | 0.965 |
| 1502 | garden | 1 | 0.965 |
| 1503 | gardeners | 1 | 0.965 |
| 1504 | gasps | 1 | 0.965 |
| 1505 | gate | 1 | 0.965 |
| 1506 | gather | 1 | 0.965 |
| 1507 | gaudy | 1 | 0.965 |
| 1508 | generally | 1 | 0.965 |
| 1509 | generations | 1 | 0.965 |
| 1510 | gentle | 1 | 0.965 |
| 1511 | genuinely | 1 | 0.965 |
| 1512 | germans | 1 | 0.965 |
| 1513 | germany | 1 | 0.965 |
| 1514 | gestures | 1 | 0.965 |
| 1515 | gifts | 1 | 0.965 |
| 1516 | gilmore | 1 | 0.965 |
| 1517 | gilmore's | 1 | 0.965 |
| 1518 | girl's | 1 | 0.965 |
| 1519 | give | 1 | 0.965 |
| 1520 | gives | 1 | 0.965 |
| 1521 | glad | 1 | 0.965 |
| 1522 | glanced | 1 | 0.965 |
| 1523 | glances | 1 | 0.965 |
| 1524 | glared | 1 | 0.965 |
| 1525 | gleaming | 1 | 0.965 |
| 1526 | glimpses | 1 | 0.965 |
| 1527 | glittering | 1 | 0.965 |
| 1528 | globe | 1 | 0.965 |
| 1529 | gloomy | 1 | 0.965 |
| 1530 | glow | 1 | 0.965 |
| 1531 | gobble | 1 | 0.965 |
| 1532 | god's | 1 | 0.965 |
| 1533 | golding | 1 | 0.965 |
| 1534 | gone | 1 | 0.965 |
| 1535 | goods | 1 | 0.965 |
| 1536 | gorgeous | 1 | 0.965 |
| 1537 | gothic | 1 | 0.965 |
| 1538 | gouging | 1 | 0.965 |
| 1539 | grabbed | 1 | 0.965 |
| 1540 | gradual | 1 | 0.965 |
| 1541 | grandpa's | 1 | 0.965 |
| 1542 | grap-, | 1 | 0.965 |
| 1543 | grappled | 1 | 0.965 |
| 1544 | graves | 1 | 0.965 |
| 1545 | gravestone | 1 | 0.965 |
| 1546 | gravestones | 1 | 0.965 |
| 1547 | graveyard | 1 | 0.965 |
| 1548 | graze | 1 | 0.965 |
| 1549 | gri-, | 1 | 0.965 |
| 1550 | grief | 1 | 0.965 |
| 1551 | grievance | 1 | 0.965 |
| 1552 | grin | 1 | 0.965 |
| 1553 | gripping | 1 | 0.965 |
| 1554 | grope | 1 | 0.965 |
| 1555 | gropes | 1 | 0.965 |
| 1556 | grunted | 1 | 0.965 |
| 1557 | grunting | 1 | 0.965 |
| 1558 | guarded | 1 | 0.965 |
| 1559 | gulped | 1 | 0.965 |
| 1560 | guy-, | 1 | 0.965 |
| 1561 | ha-, | 1 | 0.965 |
| 1562 | habituated | 1 | 0.965 |
| 1563 | halfway | 1 | 0.965 |
| 1564 | handles | 1 | 0.965 |
| 1565 | hang | 1 | 0.965 |
| 1566 | happen | 1 | 0.965 |
| 1567 | hardening | 1 | 0.965 |
| 1568 | harvest | 1 | 0.965 |
| 1569 | harvests | 1 | 0.965 |
| 1570 | haughty | 1 | 0.965 |
| 1571 | haven | 1 | 0.965 |
| 1572 | hazarded | 1 | 0.965 |
| 1573 | headed | 1 | 0.965 |
| 1574 | headset | 1 | 0.965 |
| 1575 | headstone | 1 | 0.965 |
| 1576 | heal | 1 | 0.965 |
| 1577 | healed | 1 | 0.965 |
| 1578 | hearts | 1 | 0.965 |
| 1579 | heathen | 1 | 0.965 |
| 1580 | heavy | 1 | 0.965 |
| 1581 | heed | 1 | 0.965 |
| 1582 | hence | 1 | 0.965 |
| 1583 | hercules | 1 | 0.965 |
| 1584 | herd | 1 | 0.965 |
| 1585 | heritage | 1 | 0.965 |
| 1586 | hers | 1 | 0.965 |
| 1587 | hibiscus | 1 | 0.965 |
| 1588 | hides | 1 | 0.965 |
| 1589 | high | 1 | 0.965 |
| 1590 | higher | 1 | 0.965 |
| 1591 | hispaniola | 1 | 0.965 |
| 1592 | hitherto | 1 | 0.965 |
| 1593 | hoes | 1 | 0.965 |
| 1594 | hog | 1 | 0.965 |
| 1595 | hogarth's | 1 | 0.965 |
| 1596 | hold | 1 | 0.965 |
| 1597 | holding | 1 | 0.965 |
| 1598 | honour | 1 | 0.965 |
| 1599 | hooked | 1 | 0.965 |
| 1600 | hoping | 1 | 0.965 |
| 1601 | horrible | 1 | 0.965 |
| 1602 | horse | 1 | 0.965 |
| 1603 | hospital | 1 | 0.965 |
| 1604 | hot | 1 | 0.965 |
| 1605 | hue | 1 | 0.965 |
| 1606 | hugging | 1 | 0.965 |
| 1607 | huh | 1 | 0.965 |
| 1608 | humiliated | 1 | 0.965 |
| 1609 | hundred-and-fifty | 1 | 0.965 |
| 1610 | hungry | 1 | 0.965 |
| 1611 | hunter | 1 | 0.965 |
| 1612 | hunting | 1 | 0.965 |
| 1613 | husband | 1 | 0.965 |
| 1614 | i'd | 1 | 0.965 |
| 1615 | ice | 1 | 0.965 |
| 1616 | ideologically | 1 | 0.965 |
| 1617 | idle | 1 | 0.965 |
| 1618 | idly | 1 | 0.965 |
| 1619 | ignorantly | 1 | 0.965 |
| 1620 | illegal | 1 | 0.965 |
| 1621 | illusion | 1 | 0.965 |
| 1622 | imaginations | 1 | 0.965 |
| 1623 | imagined | 1 | 0.965 |
| 1624 | imagines | 1 | 0.965 |
| 1625 | immediately | 1 | 0.965 |
| 1626 | immensities | 1 | 0.965 |
| 1627 | immortalize | 1 | 0.965 |
| 1628 | imperiously | 1 | 0.965 |
| 1629 | implanted | 1 | 0.965 |
| 1630 | impregnated | 1 | 0.965 |
| 1631 | impressing | 1 | 0.965 |
| 1632 | imprint | 1 | 0.965 |
| 1633 | imprisoned | 1 | 0.965 |
| 1634 | including | 1 | 0.965 |
| 1635 | indelicately | 1 | 0.965 |
| 1636 | indented | 1 | 0.965 |
| 1637 | indians | 1 | 0.965 |
| 1638 | indies | 1 | 0.965 |
| 1639 | indifferently | 1 | 0.965 |
| 1640 | individual | 1 | 0.965 |
| 1641 | infested | 1 | 0.965 |
| 1642 | influenced | 1 | 0.965 |
| 1643 | ing-, | 1 | 0.965 |
| 1644 | injured | 1 | 0.965 |
| 1645 | innocent | 1 | 0.965 |
| 1646 | inscribed | 1 | 0.965 |
| 1647 | inside | 1 | 0.965 |
| 1648 | insisted | 1 | 0.965 |
| 1649 | instinct | 1 | 0.965 |
| 1650 | instruct | 1 | 0.965 |
| 1651 | instruction | 1 | 0.965 |
| 1652 | instrument | 1 | 0.965 |
| 1653 | insufficient | 1 | 0.965 |
| 1654 | insurance | 1 | 0.965 |
| 1655 | intellectually | 1 | 0.965 |
| 1656 | interior | 1 | 0.965 |
| 1657 | internal | 1 | 0.965 |
| 1658 | interrupt | 1 | 0.965 |
| 1659 | invent | 1 | 0.965 |
| 1660 | inventions | 1 | 0.965 |
| 1661 | invocations | 1 | 0.965 |
| 1662 | involuntarily | 1 | 0.965 |
| 1663 | iris | 1 | 0.965 |
| 1664 | iron | 1 | 0.965 |
| 1665 | isn't | 1 | 0.965 |
| 1666 | italian | 1 | 0.965 |
| 1667 | itch | 1 | 0.965 |
| 1668 | itself | 1 | 0.965 |
| 1669 | jacket | 1 | 0.965 |
| 1670 | jamaica | 1 | 0.965 |
| 1671 | jaws | 1 | 0.965 |
| 1672 | jellyfish | 1 | 0.965 |
| 1673 | jest | 1 | 0.965 |
| 1674 | jesus | 1 | 0.965 |
| 1675 | jhal | 1 | 0.965 |
| 1676 | jocularly | 1 | 0.965 |
| 1677 | john | 1 | 0.965 |
| 1678 | johnson | 1 | 0.965 |
| 1679 | joined | 1 | 0.965 |
| 1680 | journal | 1 | 0.965 |
| 1681 | jubilation | 1 | 0.965 |
| 1682 | jump | 1 | 0.965 |
| 1683 | jumps | 1 | 0.965 |
| 1684 | keeper | 1 | 0.965 |
| 1685 | kept | 1 | 0.965 |
| 1686 | kick | 1 | 0.965 |
| 1687 | kidnapping | 1 | 0.965 |
| 1688 | kill | 1 | 0.965 |
| 1689 | killing | 1 | 0.965 |
| 1690 | kingdom | 1 | 0.965 |
| 1691 | kisses | 1 | 0.965 |
| 1692 | knight | 1 | 0.965 |
| 1693 | knives | 1 | 0.965 |
| 1694 | knows | 1 | 0.965 |
| 1695 | kwesi | 1 | 0.965 |
| 1696 | labba | 1 | 0.965 |
| 1697 | labouring | 1 | 0.965 |
| 1698 | lacked | 1 | 0.965 |
| 1699 | lame | 1 | 0.965 |
| 1700 | lamentation | 1 | 0.965 |
| 1701 | lance | 1 | 0.965 |
| 1702 | lands | 1 | 0.965 |
| 1703 | landscape | 1 | 0.965 |
| 1704 | languages | 1 | 0.965 |
| 1705 | lap | 1 | 0.965 |
| 1706 | large | 1 | 0.965 |
| 1707 | largely | 1 | 0.965 |
| 1708 | lashes | 1 | 0.965 |
| 1709 | late | 1 | 0.965 |
| 1710 | laughed | 1 | 0.965 |
| 1711 | laughter | 1 | 0.965 |
| 1712 | laurels | 1 | 0.965 |
| 1713 | lawn | 1 | 0.965 |
| 1714 | lays | 1 | 0.965 |
| 1715 | lea-, | 1 | 0.965 |
| 1716 | leading | 1 | 0.965 |
| 1717 | leaf | 1 | 0.965 |
| 1718 | lean | 1 | 0.965 |
| 1719 | learned | 1 | 0.965 |
| 1720 | leaves | 1 | 0.965 |
| 1721 | led | 1 | 0.965 |
| 1722 | legendary | 1 | 0.965 |
| 1723 | lesser | 1 | 0.965 |
| 1724 | lest | 1 | 0.965 |
| 1725 | letter | 1 | 0.965 |
| 1726 | lettering | 1 | 0.965 |
| 1727 | letterings | 1 | 0.965 |
| 1728 | letters | 1 | 0.965 |
| 1729 | level | 1 | 0.965 |
| 1730 | lewis | 1 | 0.965 |
| 1731 | liberally | 1 | 0.965 |
| 1732 | library | 1 | 0.965 |
| 1733 | lifeless | 1 | 0.965 |
| 1734 | lift | 1 | 0.965 |
| 1735 | lilies | 1 | 0.965 |
| 1736 | lined | 1 | 0.965 |
| 1737 | lingered | 1 | 0.965 |
| 1738 | linton | 1 | 0.965 |
| 1739 | lip | 1 | 0.965 |
| 1740 | liquids | 1 | 0.965 |
| 1741 | listen | 1 | 0.965 |
| 1742 | literary | 1 | 0.965 |
| 1743 | littered | 1 | 0.965 |
| 1744 | lived | 1 | 0.965 |
| 1745 | livid | 1 | 0.965 |
| 1746 | living | 1 | 0.965 |
| 1747 | livingness | 1 | 0.965 |
| 1748 | local | 1 | 0.965 |
| 1749 | lock | 1 | 0.965 |
| 1750 | lofty | 1 | 0.965 |
| 1751 | loneliness | 1 | 0.965 |
| 1752 | lonely | 1 | 0.965 |
| 1753 | longing | 1 | 0.965 |
| 1754 | longs | 1 | 0.965 |
| 1755 | looks | 1 | 0.965 |
| 1756 | loop | 1 | 0.965 |
| 1757 | loose | 1 | 0.965 |
| 1758 | loosed | 1 | 0.965 |
| 1759 | loosen | 1 | 0.965 |
| 1760 | loosening | 1 | 0.965 |
| 1761 | lopsided | 1 | 0.965 |
| 1762 | losses | 1 | 0.965 |
| 1763 | lots | 1 | 0.965 |
| 1764 | loud | 1 | 0.965 |
| 1765 | louder | 1 | 0.965 |
| 1766 | loved | 1 | 0.965 |
| 1767 | lover's | 1 | 0.965 |
| 1768 | loving | 1 | 0.965 |
| 1769 | lowers | 1 | 0.965 |
| 1770 | lucri-, | 1 | 0.965 |
| 1771 | lullaby | 1 | 0.965 |
| 1772 | lungs | 1 | 0.965 |
| 1773 | lurked | 1 | 0.965 |
| 1774 | lying | 1 | 0.965 |
| 1775 | m-, | 1 | 0.965 |
| 1776 | m-a | 1 | 0.965 |
| 1777 | machines | 1 | 0.965 |
| 1778 | magical | 1 | 0.965 |
| 1779 | magician | 1 | 0.965 |
| 1780 | maju | 1 | 0.965 |
| 1781 | male | 1 | 0.965 |
| 1782 | malice | 1 | 0.965 |
| 1783 | man's | 1 | 0.965 |
| 1784 | manner | 1 | 0.965 |
| 1785 | margins | 1 | 0.965 |
| 1786 | mark | 1 | 0.965 |
| 1787 | marked | 1 | 0.965 |
| 1788 | marks | 1 | 0.965 |
| 1789 | married | 1 | 0.965 |
| 1790 | marvelled | 1 | 0.965 |
| 1791 | mashing | 1 | 0.965 |
| 1792 | mask | 1 | 0.965 |
| 1793 | massage | 1 | 0.965 |
| 1794 | massive | 1 | 0.965 |
| 1795 | master's | 1 | 0.965 |
| 1796 | masterpiece | 1 | 0.965 |
| 1797 | materialized | 1 | 0.965 |
| 1798 | may | 1 | 0.965 |
| 1799 | maybe | 1 | 0.965 |
| 1800 | meaning | 1 | 0.965 |
| 1801 | means | 1 | 0.965 |
| 1802 | meant | 1 | 0.965 |
| 1803 | meantime | 1 | 0.965 |
| 1804 | meats | 1 | 0.965 |
| 1805 | meet | 1 | 0.965 |
| 1806 | mentio-, | 1 | 0.965 |
| 1807 | mere | 1 | 0.965 |
| 1808 | merely | 1 | 0.965 |
| 1809 | mid-ground | 1 | 0.965 |
| 1810 | mile | 1 | 0.965 |
| 1811 | mingling | 1 | 0.965 |
| 1812 | mispronouncing | 1 | 0.965 |
| 1813 | misses | 1 | 0.965 |
| 1814 | mock | 1 | 0.965 |
| 1815 | mocked | 1 | 0.965 |
| 1816 | monkeys | 1 | 0.965 |
| 1817 | morally | 1 | 0.965 |
| 1818 | mother's | 1 | 0.965 |
| 1819 | mothers | 1 | 0.965 |
| 1820 | motives | 1 | 0.965 |
| 1821 | mouldy | 1 | 0.965 |
| 1822 | mound | 1 | 0.965 |
| 1823 | movement | 1 | 0.965 |
| 1824 | movements | 1 | 0.965 |
| 1825 | moves | 1 | 0.965 |
| 1826 | mr | 1 | 0.965 |
| 1827 | multiply | 1 | 0.965 |
| 1828 | multiplying | 1 | 0.965 |
| 1829 | munificence | 1 | 0.965 |
| 1830 | murdered | 1 | 0.965 |
| 1831 | mushrooms | 1 | 0.965 |
| 1832 | muttering | 1 | 0.965 |
| 1833 | mysterious | 1 | 0.965 |
| 1834 | mysteriously | 1 | 0.965 |
| 1835 | nag | 1 | 0.965 |
| 1836 | naked | 1 | 0.965 |
| 1837 | named | 1 | 0.965 |
| 1838 | names | 1 | 0.965 |
| 1839 | narrow | 1 | 0.965 |
| 1840 | nationalistic | 1 | 0.965 |
| 1841 | nauseous | 1 | 0.965 |
| 1842 | nearly | 1 | 0.965 |
| 1843 | necessary | 1 | 0.965 |
| 1844 | necklaces | 1 | 0.965 |
| 1845 | necks | 1 | 0.965 |
| 1846 | need | 1 | 0.965 |
| 1847 | needed | 1 | 0.965 |
| 1848 | negotiate | 1 | 0.965 |
| 1849 | neo- | 1 | 0.965 |
| 1850 | nero | 1 | 0.965 |
| 1851 | net | 1 | 0.965 |
| 1852 | newly | 1 | 0.965 |
| 1853 | news | 1 | 0.965 |
| 1854 | nibbling | 1 | 0.965 |
| 1855 | niggers | 1 | 0.965 |
| 1856 | nights | 1 | 0.965 |
| 1857 | nineteen-ninety | 1 | 0.965 |
| 1858 | nineteenth | 1 | 0.965 |
| 1859 | ninety-four | 1 | 0.965 |
| 1860 | ninety-three | 1 | 0.965 |
| 1861 | ninety-two | 1 | 0.965 |
| 1862 | nipple | 1 | 0.965 |
| 1863 | noah | 1 | 0.965 |
| 1864 | nobel | 1 | 0.965 |
| 1865 | noblest | 1 | 0.965 |
| 1866 | noblewoman | 1 | 0.965 |
| 1867 | nodded | 1 | 0.965 |
| 1868 | none | 1 | 0.965 |
| 1869 | nostalgia | 1 | 0.965 |
| 1870 | nostrils | 1 | 0.965 |
| 1871 | nothingness | 1 | 0.965 |
| 1872 | noticed | 1 | 0.965 |
| 1873 | numbers | 1 | 0.965 |
| 1874 | nurture | 1 | 0.965 |
| 1875 | obliterating | 1 | 0.965 |
| 1876 | obscene | 1 | 0.965 |
| 1877 | obscure | 1 | 0.965 |
| 1878 | obsessed | 1 | 0.965 |
| 1879 | obsessively | 1 | 0.965 |
| 1880 | obstinately | 1 | 0.965 |
| 1881 | occupied | 1 | 0.965 |
| 1882 | odyssey | 1 | 0.965 |
| 1883 | offering | 1 | 0.965 |
| 1884 | office | 1 | 0.965 |
| 1885 | omeros | 1 | 0.965 |
| 1886 | one's | 1 | 0.965 |
| 1887 | ones | 1 | 0.965 |
| 1888 | oozing | 1 | 0.965 |
| 1889 | opening | 1 | 0.965 |
| 1890 | ordinariness | 1 | 0.965 |
| 1891 | ordinary | 1 | 0.965 |
| 1892 | organized | 1 | 0.965 |
| 1893 | original | 1 | 0.965 |
| 1894 | ornaments | 1 | 0.965 |
| 1895 | otters | 1 | 0.965 |
| 1896 | ours | 1 | 0.965 |
| 1897 | outrageous | 1 | 0.965 |
| 1898 | outside | 1 | 0.965 |
| 1899 | outweighed | 1 | 0.965 |
| 1900 | overcome | 1 | 0.965 |
| 1901 | overpay | 1 | 0.965 |
| 1902 | overwhelm | 1 | 0.965 |
| 1903 | overwhelmed | 1 | 0.965 |
| 1904 | oxen | 1 | 0.965 |
| 1905 | packed | 1 | 0.965 |
| 1906 | paid | 1 | 0.965 |
| 1907 | paintings | 1 | 0.965 |
| 1908 | palette | 1 | 0.965 |
| 1909 | panic | 1 | 0.965 |
| 1910 | papa | 1 | 0.965 |
| 1911 | paper | 1 | 0.965 |
| 1912 | parameters | 1 | 0.965 |
| 1913 | parcelled | 1 | 0.965 |
| 1914 | parent | 1 | 0.965 |
| 1915 | parlours | 1 | 0.965 |
| 1916 | particles | 1 | 0.965 |
| 1917 | particular | 1 | 0.965 |
| 1918 | parts | 1 | 0.965 |
| 1919 | patiently | 1 | 0.965 |
| 1920 | pattern | 1 | 0.965 |
| 1921 | patterned | 1 | 0.965 |
| 1922 | pausing | 1 | 0.965 |
| 1923 | paying | 1 | 0.965 |
| 1924 | pe-, | 1 | 0.965 |
| 1925 | pearls | 1 | 0.965 |
| 1926 | pebbles | 1 | 0.965 |
| 1927 | peculiarly | 1 | 0.965 |
| 1928 | peeled | 1 | 0.965 |
| 1929 | peeping | 1 | 0.965 |
| 1930 | peoples | 1 | 0.965 |
| 1931 | percentage | 1 | 0.965 |
| 1932 | percentages | 1 | 0.965 |
| 1933 | performance | 1 | 0.965 |
| 1934 | permission | 1 | 0.965 |
| 1935 | permitted | 1 | 0.965 |
| 1936 | person | 1 | 0.965 |
| 1937 | persuaded | 1 | 0.965 |
| 1938 | perverse | 1 | 0.965 |
| 1939 | philosophically | 1 | 0.965 |
| 1940 | photograph | 1 | 0.965 |
| 1941 | phrase | 1 | 0.965 |
| 1942 | physically | 1 | 0.965 |
| 1943 | pick | 1 | 0.965 |
| 1944 | picnic | 1 | 0.965 |
| 1945 | piece | 1 | 0.965 |
| 1946 | piercing | 1 | 0.965 |
| 1947 | pillars | 1 | 0.965 |
| 1948 | pink | 1 | 0.965 |
| 1949 | pinned | 1 | 0.965 |
| 1950 | pipe | 1 | 0.965 |
| 1951 | piranha | 1 | 0.965 |
| 1952 | pirate | 1 | 0.965 |
| 1953 | pitched | 1 | 0.965 |
| 1954 | placed | 1 | 0.965 |
| 1955 | placing | 1 | 0.965 |
| 1956 | plaid | 1 | 0.965 |
| 1957 | plainest | 1 | 0.965 |
| 1958 | plantains | 1 | 0.965 |
| 1959 | plaque | 1 | 0.965 |
| 1960 | plastic | 1 | 0.965 |
| 1961 | plato | 1 | 0.965 |
| 1962 | playful | 1 | 0.965 |
| 1963 | playground | 1 | 0.965 |
| 1964 | playing | 1 | 0.965 |
| 1965 | pleased | 1 | 0.965 |
| 1966 | pleasing | 1 | 0.965 |
| 1967 | plough | 1 | 0.965 |
| 1968 | plucked | 1 | 0.965 |
| 1969 | plucks | 1 | 0.965 |
| 1970 | po-, | 1 | 0.965 |
| 1971 | pockets | 1 | 0.965 |
| 1972 | poetic | 1 | 0.965 |
| 1973 | poisoned | 1 | 0.965 |
| 1974 | poofs | 1 | 0.965 |
| 1975 | pope | 1 | 0.965 |
| 1976 | portent | 1 | 0.965 |
| 1977 | portions | 1 | 0.965 |
| 1978 | possess | 1 | 0.965 |
| 1979 | possessed | 1 | 0.965 |
| 1980 | possession | 1 | 0.965 |
| 1981 | possessions | 1 | 0.965 |
| 1982 | potions | 1 | 0.965 |
| 1983 | power | 1 | 0.965 |
| 1984 | practised | 1 | 0.965 |
| 1985 | praise | 1 | 0.965 |
| 1986 | preacher | 1 | 0.965 |
| 1987 | precarious | 1 | 0.965 |
| 1988 | precious | 1 | 0.965 |
| 1989 | prefer | 1 | 0.965 |
| 1990 | pregnancy | 1 | 0.965 |
| 1991 | preparations | 1 | 0.965 |
| 1992 | prepared | 1 | 0.965 |
| 1993 | press | 1 | 0.965 |
| 1994 | pretending | 1 | 0.965 |
| 1995 | prick | 1 | 0.965 |
| 1996 | priest | 1 | 0.965 |
| 1997 | prince | 1 | 0.965 |
| 1998 | 1 | 0.965 | |
| 1999 | pristine | 1 | 0.965 |
| 2000 | privilege | 1 | 0.965 |
| 2001 | prize | 1 | 0.965 |
| 2002 | professor | 1 | 0.965 |
| 2003 | profitably | 1 | 0.965 |
| 2004 | profound | 1 | 0.965 |
| 2005 | profusion | 1 | 0.965 |
| 2006 | property | 1 | 0.965 |
| 2007 | prophecy | 1 | 0.965 |
| 2008 | prophesy | 1 | 0.965 |
| 2009 | proprietor | 1 | 0.965 |
| 2010 | proprietors | 1 | 0.965 |
| 2011 | protectively | 1 | 0.965 |
| 2012 | proudly | 1 | 0.965 |
| 2013 | provoked | 1 | 0.965 |
| 2014 | pseudo-jamaican | 1 | 0.965 |
| 2015 | published | 1 | 0.965 |
| 2016 | puffed | 1 | 0.965 |
| 2017 | punishment | 1 | 0.965 |
| 2018 | purchase | 1 | 0.965 |
| 2019 | purity | 1 | 0.965 |
| 2020 | purple | 1 | 0.965 |
| 2021 | purpose | 1 | 0.965 |
| 2022 | push | 1 | 0.965 |
| 2023 | pushing | 1 | 0.965 |
| 2024 | pussy | 1 | 0.965 |
| 2025 | puzzled | 1 | 0.965 |
| 2026 | qualification | 1 | 0.965 |
| 2027 | quality | 1 | 0.965 |
| 2028 | queers | 1 | 0.965 |
| 2029 | quell | 1 | 0.965 |
| 2030 | question | 1 | 0.965 |
| 2031 | queue | 1 | 0.965 |
| 2032 | quickened | 1 | 0.965 |
| 2033 | rab-, | 1 | 0.965 |
| 2034 | racks | 1 | 0.965 |
| 2035 | raggedly | 1 | 0.965 |
| 2036 | rags | 1 | 0.965 |
| 2037 | rainwater | 1 | 0.965 |
| 2038 | raised | 1 | 0.965 |
| 2039 | raises | 1 | 0.965 |
| 2040 | rank | 1 | 0.965 |
| 2041 | rape | 1 | 0.965 |
| 2042 | rapture | 1 | 0.965 |
| 2043 | rash | 1 | 0.965 |
| 2044 | rastafarian | 1 | 0.965 |
| 2045 | rather | 1 | 0.965 |
| 2046 | rats | 1 | 0.965 |
| 2047 | raven | 1 | 0.965 |
| 2048 | ravish | 1 | 0.965 |
| 2049 | reaches | 1 | 0.965 |
| 2050 | ready | 1 | 0.965 |
| 2051 | realization | 1 | 0.965 |
| 2052 | realize | 1 | 0.965 |
| 2053 | reaped | 1 | 0.965 |
| 2054 | rear | 1 | 0.965 |
| 2055 | reassurance | 1 | 0.965 |
| 2056 | received | 1 | 0.965 |
| 2057 | receives | 1 | 0.965 |
| 2058 | reckoning | 1 | 0.965 |
| 2059 | reclaimed | 1 | 0.965 |
| 2060 | reclimbing | 1 | 0.965 |
| 2061 | recognition | 1 | 0.965 |
| 2062 | reconceptualizing | 1 | 0.965 |
| 2063 | recover | 1 | 0.965 |
| 2064 | recreate | 1 | 0.965 |
| 2065 | redemptive | 1 | 0.965 |
| 2066 | refashioned | 1 | 0.965 |
| 2067 | reflect | 1 | 0.965 |
| 2068 | reflected | 1 | 0.965 |
| 2069 | reflection | 1 | 0.965 |
| 2070 | regain | 1 | 0.965 |
| 2071 | regular | 1 | 0.965 |
| 2072 | relief | 1 | 0.965 |
| 2073 | remaining | 1 | 0.965 |
| 2074 | remembered | 1 | 0.965 |
| 2075 | remove | 1 | 0.965 |
| 2076 | renewed | 1 | 0.965 |
| 2077 | reparation | 1 | 0.965 |
| 2078 | repeated | 1 | 0.965 |
| 2079 | report | 1 | 0.965 |
| 2080 | research | 1 | 0.965 |
| 2081 | resolve | 1 | 0.965 |
| 2082 | restaurants | 1 | 0.965 |
| 2083 | restoring | 1 | 0.965 |
| 2084 | restricted | 1 | 0.965 |
| 2085 | result | 1 | 0.965 |
| 2086 | resurrection | 1 | 0.965 |
| 2087 | retreat | 1 | 0.965 |
| 2088 | retreated | 1 | 0.965 |
| 2089 | return | 1 | 0.965 |
| 2090 | returns | 1 | 0.965 |
| 2091 | revelation | 1 | 0.965 |
| 2092 | revengefulness | 1 | 0.965 |
| 2093 | reverence | 1 | 0.965 |
| 2094 | revisualization | 1 | 0.965 |
| 2095 | revisualizing | 1 | 0.965 |
| 2096 | revive | 1 | 0.965 |
| 2097 | rhetoric | 1 | 0.965 |
| 2098 | riches | 1 | 0.965 |
| 2099 | richly | 1 | 0.965 |
| 2100 | richness | 1 | 0.965 |
| 2101 | rid-, | 1 | 0.965 |
| 2102 | rioting | 1 | 0.965 |
| 2103 | ripped | 1 | 0.965 |
| 2104 | rise | 1 | 0.965 |
| 2105 | ritual | 1 | 0.965 |
| 2106 | roam | 1 | 0.965 |
| 2107 | roamed | 1 | 0.965 |
| 2108 | roar | 1 | 0.965 |
| 2109 | rolling | 1 | 0.965 |
| 2110 | romantic | 1 | 0.965 |
| 2111 | romantics | 1 | 0.965 |
| 2112 | roni-, | 1 | 0.965 |
| 2113 | rooted | 1 | 0.965 |
| 2114 | roots | 1 | 0.965 |
| 2115 | rope | 1 | 0.965 |
| 2116 | ropes | 1 | 0.965 |
| 2117 | rose | 1 | 0.965 |
| 2118 | rouge | 1 | 0.965 |
| 2119 | roundness | 1 | 0.965 |
| 2120 | royalties | 1 | 0.965 |
| 2121 | royalty | 1 | 0.965 |
| 2122 | rub | 1 | 0.965 |
| 2123 | rubies | 1 | 0.965 |
| 2124 | runs | 1 | 0.965 |
| 2125 | rush | 1 | 0.965 |
| 2126 | rushed | 1 | 0.965 |
| 2127 | ruskin | 1 | 0.965 |
| 2128 | rusty | 1 | 0.965 |
| 2129 | saba | 1 | 0.965 |
| 2130 | sadu | 1 | 0.965 |
| 2131 | safety | 1 | 0.965 |
| 2132 | sailor's | 1 | 0.965 |
| 2133 | sale | 1 | 0.965 |
| 2134 | salty | 1 | 0.965 |
| 2135 | sat | 1 | 0.965 |
| 2136 | saturday | 1 | 0.965 |
| 2137 | savagely | 1 | 0.965 |
| 2138 | saving | 1 | 0.965 |
| 2139 | says | 1 | 0.965 |
| 2140 | scaling | 1 | 0.965 |
| 2141 | scarce | 1 | 0.965 |
| 2142 | scarify | 1 | 0.965 |
| 2143 | scatter | 1 | 0.965 |
| 2144 | scattered | 1 | 0.965 |
| 2145 | scavenged | 1 | 0.965 |
| 2146 | scented | 1 | 0.965 |
| 2147 | scholarship | 1 | 0.965 |
| 2148 | scorn | 1 | 0.965 |
| 2149 | screamed | 1 | 0.965 |
| 2150 | screaming | 1 | 0.965 |
| 2151 | screeching | 1 | 0.965 |
| 2152 | scrolls | 1 | 0.965 |
| 2153 | sea's | 1 | 0.965 |
| 2154 | seal's | 1 | 0.965 |
| 2155 | secondborn | 1 | 0.965 |
| 2156 | seconds | 1 | 0.965 |
| 2157 | secreted | 1 | 0.965 |
| 2158 | security | 1 | 0.965 |
| 2159 | seed | 1 | 0.965 |
| 2160 | seeing | 1 | 0.965 |
| 2161 | seeking | 1 | 0.965 |
| 2162 | seen | 1 | 0.965 |
| 2163 | seeped | 1 | 0.965 |
| 2164 | self- | 1 | 0.965 |
| 2165 | selflessly | 1 | 0.965 |
| 2166 | sell | 1 | 0.965 |
| 2167 | selling | 1 | 0.965 |
| 2168 | senior | 1 | 0.965 |
| 2169 | senses | 1 | 0.965 |
| 2170 | sensing | 1 | 0.965 |
| 2171 | serious | 1 | 0.965 |
| 2172 | seriously | 1 | 0.965 |
| 2173 | services | 1 | 0.965 |
| 2174 | seven | 1 | 0.965 |
| 2175 | seventeen | 1 | 0.965 |
| 2176 | seventeen-eighties | 1 | 0.965 |
| 2177 | sh-, | 1 | 0.965 |
| 2178 | shaped | 1 | 0.965 |
| 2179 | shaping | 1 | 0.965 |
| 2180 | shark | 1 | 0.965 |
| 2181 | sharp | 1 | 0.965 |
| 2182 | sharpening | 1 | 0.965 |
| 2183 | shave | 1 | 0.965 |
| 2184 | shelf | 1 | 0.965 |
| 2185 | shells | 1 | 0.965 |
| 2186 | shield | 1 | 0.965 |
| 2187 | shiny | 1 | 0.965 |
| 2188 | shipped | 1 | 0.965 |
| 2189 | ships | 1 | 0.965 |
| 2190 | shit | 1 | 0.965 |
| 2191 | shoals | 1 | 0.965 |
| 2192 | shocked | 1 | 0.965 |
| 2193 | shone | 1 | 0.965 |
| 2194 | shops | 1 | 0.965 |
| 2195 | short | 1 | 0.965 |
| 2196 | shorten | 1 | 0.965 |
| 2197 | shouted | 1 | 0.965 |
| 2198 | shove | 1 | 0.965 |
| 2199 | showed | 1 | 0.965 |
| 2200 | shows | 1 | 0.965 |
| 2201 | shrieks | 1 | 0.965 |
| 2202 | shrimps | 1 | 0.965 |
| 2203 | shuddered | 1 | 0.965 |
| 2204 | shut | 1 | 0.965 |
| 2205 | shy | 1 | 0.965 |
| 2206 | sickle | 1 | 0.965 |
| 2207 | sideways | 1 | 0.965 |
| 2208 | silent | 1 | 0.965 |
| 2209 | silently | 1 | 0.965 |
| 2210 | simpler | 1 | 0.965 |
| 2211 | sin | 1 | 0.965 |
| 2212 | sinking | 1 | 0.965 |
| 2213 | sinning | 1 | 0.965 |
| 2214 | sixty | 1 | 0.965 |
| 2215 | skels | 1 | 0.965 |
| 2216 | sketches | 1 | 0.965 |
| 2217 | skirt | 1 | 0.965 |
| 2218 | sky's | 1 | 0.965 |
| 2219 | slag | 1 | 0.965 |
| 2220 | slapped | 1 | 0.965 |
| 2221 | slaps | 1 | 0.965 |
| 2222 | sleeping | 1 | 0.965 |
| 2223 | slight | 1 | 0.965 |
| 2224 | slithers | 1 | 0.965 |
| 2225 | slob | 1 | 0.965 |
| 2226 | slow | 1 | 0.965 |
| 2227 | sluggishly | 1 | 0.965 |
| 2228 | smell | 1 | 0.965 |
| 2229 | smells | 1 | 0.965 |
| 2230 | smile | 1 | 0.965 |
| 2231 | smiling | 1 | 0.965 |
| 2232 | smoked | 1 | 0.965 |
| 2233 | smooched | 1 | 0.965 |
| 2234 | smouldered | 1 | 0.965 |
| 2235 | snakes | 1 | 0.965 |
| 2236 | snaps | 1 | 0.965 |
| 2237 | sniffs | 1 | 0.965 |
| 2238 | snorting | 1 | 0.965 |
| 2239 | so-, | 1 | 0.965 |
| 2240 | social | 1 | 0.965 |
| 2241 | sofa | 1 | 0.965 |
| 2242 | softening | 1 | 0.965 |
| 2243 | soothe | 1 | 0.965 |
| 2244 | soothes | 1 | 0.965 |
| 2245 | sort | 1 | 0.965 |
| 2246 | sounds | 1 | 0.965 |
| 2247 | south | 1 | 0.965 |
| 2248 | southernly | 1 | 0.965 |
| 2249 | spanking | 1 | 0.965 |
| 2250 | spears | 1 | 0.965 |
| 2251 | spectacle | 1 | 0.965 |
| 2252 | speed | 1 | 0.965 |
| 2253 | spheres | 1 | 0.965 |
| 2254 | spills | 1 | 0.965 |
| 2255 | spite | 1 | 0.965 |
| 2256 | sponges | 1 | 0.965 |
| 2257 | spontaneously | 1 | 0.965 |
| 2258 | sport | 1 | 0.965 |
| 2259 | spot | 1 | 0.965 |
| 2260 | sprawled | 1 | 0.965 |
| 2261 | sprawling | 1 | 0.965 |
| 2262 | sprightly | 1 | 0.965 |
| 2263 | spurting | 1 | 0.965 |
| 2264 | squirming | 1 | 0.965 |
| 2265 | stampeded | 1 | 0.965 |
| 2266 | standing | 1 | 0.965 |
| 2267 | stares | 1 | 0.965 |
| 2268 | start | 1 | 0.965 |
| 2269 | steadfast | 1 | 0.965 |
| 2270 | stepping | 1 | 0.965 |
| 2271 | steps | 1 | 0.965 |
| 2272 | sternly | 1 | 0.965 |
| 2273 | sticking | 1 | 0.965 |
| 2274 | stiff | 1 | 0.965 |
| 2275 | stifle | 1 | 0.965 |
| 2276 | stomach | 1 | 0.965 |
| 2277 | stomp | 1 | 0.965 |
| 2278 | stonemason | 1 | 0.965 |
| 2279 | stones | 1 | 0.965 |
| 2280 | stopped | 1 | 0.965 |
| 2281 | stopping | 1 | 0.965 |
| 2282 | stories | 1 | 0.965 |
| 2283 | storms | 1 | 0.965 |
| 2284 | stormy | 1 | 0.965 |
| 2285 | stout | 1 | 0.965 |
| 2286 | straight | 1 | 0.965 |
| 2287 | streaked | 1 | 0.965 |
| 2288 | streets | 1 | 0.965 |
| 2289 | strict | 1 | 0.965 |
| 2290 | stripes | 1 | 0.965 |
| 2291 | striptease | 1 | 0.965 |
| 2292 | strong | 1 | 0.965 |
| 2293 | stronger | 1 | 0.965 |
| 2294 | struck | 1 | 0.965 |
| 2295 | structures | 1 | 0.965 |
| 2296 | struggled | 1 | 0.965 |
| 2297 | stubble | 1 | 0.965 |
| 2298 | stubbornness | 1 | 0.965 |
| 2299 | stuck | 1 | 0.965 |
| 2300 | student | 1 | 0.965 |
| 2301 | study | 1 | 0.965 |
| 2302 | stuff | 1 | 0.965 |
| 2303 | stupefaction | 1 | 0.965 |
| 2304 | style | 1 | 0.965 |
| 2305 | subdue | 1 | 0.965 |
| 2306 | substantial | 1 | 0.965 |
| 2307 | subtracted | 1 | 0.965 |
| 2308 | sucks | 1 | 0.965 |
| 2309 | suffer | 1 | 0.965 |
| 2310 | suffered | 1 | 0.965 |
| 2311 | suffering | 1 | 0.965 |
| 2312 | suffolk | 1 | 0.965 |
| 2313 | sugared | 1 | 0.965 |
| 2314 | sugarloaves | 1 | 0.965 |
| 2315 | suit | 1 | 0.965 |
| 2316 | sulks | 1 | 0.965 |
| 2317 | sunken | 1 | 0.965 |
| 2318 | supervision | 1 | 0.965 |
| 2319 | suppose | 1 | 0.965 |
| 2320 | suppressing | 1 | 0.965 |
| 2321 | surmise | 1 | 0.965 |
| 2322 | surrounded | 1 | 0.965 |
| 2323 | surrounding | 1 | 0.965 |
| 2324 | survive | 1 | 0.965 |
| 2325 | sustaining | 1 | 0.965 |
| 2326 | swallow | 1 | 0.965 |
| 2327 | swallowed | 1 | 0.965 |
| 2328 | swallowing | 1 | 0.965 |
| 2329 | swarming | 1 | 0.965 |
| 2330 | swatter | 1 | 0.965 |
| 2331 | swearing | 1 | 0.965 |
| 2332 | sweat | 1 | 0.965 |
| 2333 | swelled | 1 | 0.965 |
| 2334 | swelling | 1 | 0.965 |
| 2335 | swiftly | 1 | 0.965 |
| 2336 | swim | 1 | 0.965 |
| 2337 | swimming | 1 | 0.965 |
| 2338 | switched | 1 | 0.965 |
| 2339 | sword | 1 | 0.965 |
| 2340 | swords | 1 | 0.965 |
| 2341 | t-, | 1 | 0.965 |
| 2342 | table | 1 | 0.965 |
| 2343 | takes | 1 | 0.965 |
| 2344 | taking | 1 | 0.965 |
| 2345 | tally | 1 | 0.965 |
| 2346 | tanda | 1 | 0.965 |
| 2347 | tastes | 1 | 0.965 |
| 2348 | taught | 1 | 0.965 |
| 2349 | taxes | 1 | 0.965 |
| 2350 | taxman | 1 | 0.965 |
| 2351 | tears | 1 | 0.965 |
| 2352 | temples | 1 | 0.965 |
| 2353 | tended | 1 | 0.965 |
| 2354 | terribly | 1 | 0.965 |
| 2355 | terror | 1 | 0.965 |
| 2356 | test | 1 | 0.965 |
| 2357 | tested | 1 | 0.965 |
| 2358 | texture | 1 | 0.965 |
| 2359 | th-, | 1 | 0.965 |
| 2360 | theme | 1 | 0.965 |
| 2361 | they'll | 1 | 0.965 |
| 2362 | thin | 1 | 0.965 |
| 2363 | thinking | 1 | 0.965 |
| 2364 | thinks | 1 | 0.965 |
| 2365 | thistlewood's | 1 | 0.965 |
| 2366 | thorns | 1 | 0.965 |
| 2367 | thousand-and-a-half | 1 | 0.965 |
| 2368 | threatening | 1 | 0.965 |
| 2369 | threatens | 1 | 0.965 |
| 2370 | three-hundred | 1 | 0.965 |
| 2371 | throat | 1 | 0.965 |
| 2372 | thumb | 1 | 0.965 |
| 2373 | thumbed | 1 | 0.965 |
| 2374 | tie | 1 | 0.965 |
| 2375 | tied | 1 | 0.965 |
| 2376 | tightly | 1 | 0.965 |
| 2377 | tiny | 1 | 0.965 |
| 2378 | tired | 1 | 0.965 |
| 2379 | tiring | 1 | 0.965 |
| 2380 | titanic | 1 | 0.965 |
| 2381 | tobacco | 1 | 0.965 |
| 2382 | toenail | 1 | 0.965 |
| 2383 | together | 1 | 0.965 |
| 2384 | told | 1 | 0.965 |
| 2385 | tolerance | 1 | 0.965 |
| 2386 | tomb | 1 | 0.965 |
| 2387 | tomb's | 1 | 0.965 |
| 2388 | tongueless | 1 | 0.965 |
| 2389 | tonight | 1 | 0.965 |
| 2390 | tools | 1 | 0.965 |
| 2391 | touch | 1 | 0.965 |
| 2392 | tour | 1 | 0.965 |
| 2393 | trace | 1 | 0.965 |
| 2394 | trade | 1 | 0.965 |
| 2395 | trader | 1 | 0.965 |
| 2396 | tragedy | 1 | 0.965 |
| 2397 | trailing | 1 | 0.965 |
| 2398 | train | 1 | 0.965 |
| 2399 | transformation | 1 | 0.965 |
| 2400 | traveller | 1 | 0.965 |
| 2401 | treasure | 1 | 0.965 |
| 2402 | tree | 1 | 0.965 |
| 2403 | trench | 1 | 0.965 |
| 2404 | trespass | 1 | 0.965 |
| 2405 | tribute | 1 | 0.965 |
| 2406 | triumph | 1 | 0.965 |
| 2407 | trojan | 1 | 0.965 |
| 2408 | trooped | 1 | 0.965 |
| 2409 | trouble | 1 | 0.965 |
| 2410 | troy | 1 | 0.965 |
| 2411 | trumpets | 1 | 0.965 |
| 2412 | trussed | 1 | 0.965 |
| 2413 | truth | 1 | 0.965 |
| 2414 | try | 1 | 0.965 |
| 2415 | tugged | 1 | 0.965 |
| 2416 | tumble | 1 | 0.965 |
| 2417 | tune | 1 | 0.965 |
| 2418 | twenty | 1 | 0.965 |
| 2419 | twenty-five | 1 | 0.965 |
| 2420 | twigs | 1 | 0.965 |
| 2421 | twinkling | 1 | 0.965 |
| 2422 | twirls | 1 | 0.965 |
| 2423 | twisted | 1 | 0.965 |
| 2424 | two-hundred | 1 | 0.965 |
| 2425 | type | 1 | 0.965 |
| 2426 | u-, | 1 | 0.965 |
| 2427 | unable | 1 | 0.965 |
| 2428 | unborn | 1 | 0.965 |
| 2429 | underpinnings | 1 | 0.965 |
| 2430 | understand | 1 | 0.965 |
| 2431 | undertaker's | 1 | 0.965 |
| 2432 | unending | 1 | 0.965 |
| 2433 | unfamiliar | 1 | 0.965 |
| 2434 | unfolding | 1 | 0.965 |
| 2435 | unfulfilled | 1 | 0.965 |
| 2436 | ungratefully | 1 | 0.965 |
| 2437 | unhappiness | 1 | 0.965 |
| 2438 | unhewn | 1 | 0.965 |
| 2439 | universal | 1 | 0.965 |
| 2440 | unlike | 1 | 0.965 |
| 2441 | unnamed | 1 | 0.965 |
| 2442 | unpastes | 1 | 0.965 |
| 2443 | unpublished | 1 | 0.965 |
| 2444 | unties | 1 | 0.965 |
| 2445 | unwrap | 1 | 0.965 |
| 2446 | urien | 1 | 0.965 |
| 2447 | using | 1 | 0.965 |
| 2448 | utter | 1 | 0.965 |
| 2449 | valour | 1 | 0.965 |
| 2450 | value | 1 | 0.965 |
| 2451 | vanquished | 1 | 0.965 |
| 2452 | vaster | 1 | 0.965 |
| 2453 | veil | 1 | 0.965 |
| 2454 | venture | 1 | 0.965 |
| 2455 | ventured | 1 | 0.965 |
| 2456 | ver-, | 1 | 0.965 |
| 2457 | videos | 1 | 0.965 |
| 2458 | view | 1 | 0.965 |
| 2459 | viewer's | 1 | 0.965 |
| 2460 | villagers | 1 | 0.965 |
| 2461 | villages | 1 | 0.965 |
| 2462 | violent | 1 | 0.965 |
| 2463 | wa-, | 1 | 0.965 |
| 2464 | wake | 1 | 0.965 |
| 2465 | walking | 1 | 0.965 |
| 2466 | walls | 1 | 0.965 |
| 2467 | wander | 1 | 0.965 |
| 2468 | wandered | 1 | 0.965 |
| 2469 | waning | 1 | 0.965 |
| 2470 | wanking | 1 | 0.965 |
| 2471 | war | 1 | 0.965 |
| 2472 | warehouse | 1 | 0.965 |
| 2473 | wares | 1 | 0.965 |
| 2474 | warriors | 1 | 0.965 |
| 2475 | wash | 1 | 0.965 |
| 2476 | washed | 1 | 0.965 |
| 2477 | washing | 1 | 0.965 |
| 2478 | wasn't | 1 | 0.965 |
| 2479 | watches | 1 | 0.965 |
| 2480 | waves | 1 | 0.965 |
| 2481 | wayward | 1 | 0.965 |
| 2482 | weapon | 1 | 0.965 |
| 2483 | wears | 1 | 0.965 |
| 2484 | weaves | 1 | 0.965 |
| 2485 | weaving | 1 | 0.965 |
| 2486 | week | 1 | 0.965 |
| 2487 | weeks | 1 | 0.965 |
| 2488 | weep | 1 | 0.965 |
| 2489 | weeping | 1 | 0.965 |
| 2490 | western | 1 | 0.965 |
| 2491 | wet | 1 | 0.965 |
| 2492 | what's | 1 | 0.965 |
| 2493 | wheeze | 1 | 0.965 |
| 2494 | whereby | 1 | 0.965 |
| 2495 | wherever | 1 | 0.965 |
| 2496 | whether | 1 | 0.965 |
| 2497 | whim | 1 | 0.965 |
| 2498 | whip | 1 | 0.965 |
| 2499 | whips | 1 | 0.965 |
| 2500 | whores | 1 | 0.965 |
| 2501 | wife | 1 | 0.965 |
| 2502 | wild | 1 | 0.965 |
| 2503 | wildest | 1 | 0.965 |
| 2504 | willed | 1 | 0.965 |
| 2505 | win | 1 | 0.965 |
| 2506 | windows | 1 | 0.965 |
| 2507 | wine | 1 | 0.965 |
| 2508 | wings | 1 | 0.965 |
| 2509 | winking | 1 | 0.965 |
| 2510 | winning | 1 | 0.965 |
| 2511 | wipe | 1 | 0.965 |
| 2512 | wish | 1 | 0.965 |
| 2513 | wished | 1 | 0.965 |
| 2514 | withdrawal | 1 | 0.965 |
| 2515 | witter | 1 | 0.965 |
| 2516 | woke | 1 | 0.965 |
| 2517 | won | 1 | 0.965 |
| 2518 | wonderland | 1 | 0.965 |
| 2519 | workers | 1 | 0.965 |
| 2520 | works | 1 | 0.965 |
| 2521 | wriggled | 1 | 0.965 |
| 2522 | wringing | 1 | 0.965 |
| 2523 | wrinkled | 1 | 0.965 |
| 2524 | writhes | 1 | 0.965 |
| 2525 | yard | 1 | 0.965 |
| 2526 | year | 1 | 0.965 |
| 2527 | yolk | 1 | 0.965 |
| 2528 | zong | 1 | 0.965 |
2.2 Association scores
Next, we calculate the association scores with a call to assoc_scores(), providing first the target frequency list flist_target and then the reference frequency list flist_ref. We’ll store the result in a variable called scores_kw. Once we have our scores_kw, we can sort them by PMI and by signed \(G^2\).
# calculate scores
scores_kw <- assoc_scores(flist_target, flist_ref)
# print scores, sorted by PMI
print(scores_kw, sort_order = "PMI")Association scores (types in list: 575, sort order criterion: PMI)
type a PMI G_signed| b c d dir exp_a DP_rows
1 manu 15.5 7.25 152.3|10346 0.5 1614253 1 0.102 0.001
2 gladstone 13.5 7.24 132.2|10348 0.5 1614253 1 0.089 0.001
3 rohini 10.5 7.23 102.1|10352 0.5 1614253 1 0.070 0.001
4 troilus 9.5 7.22 92.1|10352 0.5 1614253 1 0.064 0.001
5 thistlewood 7.5 7.20 72.1|10354 0.5 1614253 1 0.051 0.001
6 guyanese 6.5 7.19 62.1|10356 0.5 1614253 1 0.045 0.001
7 stillborn 6.5 7.19 62.1|10356 0.5 1614253 1 0.045 0.001
8 cabin 5.5 7.17 52.2|10356 0.5 1614253 1 0.038 0.001
9 kampta 5.5 7.17 52.2|10356 0.5 1614253 1 0.038 0.001
10 guyana 9.0 7.14 84.5|10352 1.0 1614251 1 0.064 0.001
11 anarch 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
12 aperture 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
13 coolie 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
14 criseyde 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
15 ellar 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
16 grandpa 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
17 kaka 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
18 lachrimae 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
19 overboard 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
20 awakened 7.0 7.10 64.8|10354 1.0 1614251 1 0.051 0.001
...
<number of extra columns to the right: 7># print scores, sorted by G_signed
print(scores_kw, sort_order = "G_signed")Association scores (types in list: 575, sort order criterion: G_signed)
type a PMI G_signed| b c d dir exp_a
1 her 106.0 4.14 420.1|10255 838.0 1613414 1 6.020
2 she 81.0 3.55 256.0|10280 1005.0 1613247 1 6.926
3 slavery 24.0 6.88 206.8|10337 8.0 1614244 1 0.204
4 sea 28.0 5.69 176.1|10333 57.0 1614195 1 0.542
5 manu 15.5 7.25 152.3|10346 0.5 1614253 1 0.102
6 turner 17.0 6.79 143.0|10344 7.0 1614245 1 0.153
7 gladstone 13.5 7.24 132.2|10348 0.5 1614253 1 0.089
8 my 62.0 2.70 129.4|10299 1432.0 1612820 1 9.528
9 he 102.0 1.76 107.0|10259 4612.0 1609640 1 30.064
10 his 64.0 2.30 103.9|10297 1968.0 1612284 1 12.959
11 rohini 10.5 7.23 102.1|10352 0.5 1614253 1 0.070
12 nigger 11.0 6.95 96.7|10350 3.0 1614249 1 0.089
13 african 15.0 5.64 93.2|10346 32.0 1614220 1 0.300
14 troilus 9.5 7.22 92.1|10352 0.5 1614253 1 0.064
15 shah 10.0 7.03 90.3|10351 2.0 1614250 1 0.077
16 dead 19.0 4.60 87.6|10342 104.0 1614148 1 0.784
17 shop 15.0 5.39 87.1|10346 41.0 1614211 1 0.357
18 guyana 9.0 7.14 84.5|10352 1.0 1614251 1 0.064
19 him 36.0 2.87 82.2|10325 739.0 1613513 1 4.943
20 fish 13.0 5.38 75.2|10348 36.0 1614216 1 0.312
...
<number of extra columns to the right: 8>It might seem disconcerting that some frequencies (a column) have decimals. This is because some values in the contingency table were 0 and 0.5 was added to all the cells to avoid divisions by 0 (the Haldane-Anscombe correction). If you would rather use a different small number in these cases, you can set haldane = FALSE in your assoc_scores() call and set your desired small value in the small_pos argument.
2.3 Filtering of keywords by PMI and signed \(G^2\)
We can use filter() to filter the keywords (i.e. the rows of scores_kw) by PMI and signed \(G^2\). We’ll store the result in a variable called top_scores_kw and again print the result, first sorted by PMI, then by signed \(G^2\). This allows us to explore which words are ranked higher by each of the measures.
top_scores_kw <- scores_kw %>%
filter(PMI >= 2 & G_signed >= 2)
# print top_scores_kw, sorted by PMI
top_scores_kw %>%
print(sort_order = "PMI")Association scores (types in list: 269, sort order criterion: PMI)
type a PMI G_signed| b c d dir exp_a DP_rows
1 manu 15.5 7.25 152.3|10346 0.5 1614253 1 0.102 0.001
2 gladstone 13.5 7.24 132.2|10348 0.5 1614253 1 0.089 0.001
3 rohini 10.5 7.23 102.1|10352 0.5 1614253 1 0.070 0.001
4 troilus 9.5 7.22 92.1|10352 0.5 1614253 1 0.064 0.001
5 thistlewood 7.5 7.20 72.1|10354 0.5 1614253 1 0.051 0.001
6 guyanese 6.5 7.19 62.1|10356 0.5 1614253 1 0.045 0.001
7 stillborn 6.5 7.19 62.1|10356 0.5 1614253 1 0.045 0.001
8 cabin 5.5 7.17 52.2|10356 0.5 1614253 1 0.038 0.001
9 kampta 5.5 7.17 52.2|10356 0.5 1614253 1 0.038 0.001
10 guyana 9.0 7.14 84.5|10352 1.0 1614251 1 0.064 0.001
11 anarch 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
12 aperture 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
13 coolie 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
14 criseyde 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
15 ellar 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
16 grandpa 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
17 kaka 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
18 lachrimae 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
19 overboard 4.5 7.14 42.3|10358 0.5 1614253 1 0.032 0.000
20 awakened 7.0 7.10 64.8|10354 1.0 1614251 1 0.051 0.001
...
<number of extra columns to the right: 7>Association scores (types in list: 269, sort order criterion: G_signed)
type a PMI G_signed| b c d dir exp_a
1 her 106.0 4.14 420.1|10255 838.0 1613414 1 6.020
2 she 81.0 3.55 256.0|10280 1005.0 1613247 1 6.926
3 slavery 24.0 6.88 206.8|10337 8.0 1614244 1 0.204
4 sea 28.0 5.69 176.1|10333 57.0 1614195 1 0.542
5 manu 15.5 7.25 152.3|10346 0.5 1614253 1 0.102
6 turner 17.0 6.79 143.0|10344 7.0 1614245 1 0.153
7 gladstone 13.5 7.24 132.2|10348 0.5 1614253 1 0.089
8 my 62.0 2.70 129.4|10299 1432.0 1612820 1 9.528
9 his 64.0 2.30 103.9|10297 1968.0 1612284 1 12.959
10 rohini 10.5 7.23 102.1|10352 0.5 1614253 1 0.070
11 nigger 11.0 6.95 96.7|10350 3.0 1614249 1 0.089
12 african 15.0 5.64 93.2|10346 32.0 1614220 1 0.300
13 troilus 9.5 7.22 92.1|10352 0.5 1614253 1 0.064
14 shah 10.0 7.03 90.3|10351 2.0 1614250 1 0.077
15 dead 19.0 4.60 87.6|10342 104.0 1614148 1 0.784
16 shop 15.0 5.39 87.1|10346 41.0 1614211 1 0.357
17 guyana 9.0 7.14 84.5|10352 1.0 1614251 1 0.064
18 him 36.0 2.87 82.2|10325 739.0 1613513 1 4.943
19 fish 13.0 5.38 75.2|10348 36.0 1614216 1 0.312
20 poem 15.0 4.81 73.7|10346 69.0 1614183 1 0.536
...
<number of extra columns to the right: 8>Here you can keep reading to see the steps for collocation analysis or skip to the Section 4 for tips on how to move forward.
3 Collocation analysis
For collocation analysis, we will use the full BASE corpus (fnames_BASE) and, instead of the freqlist() function, the surf_cooc() function. This function requires a re_node argument that is a regular expression capturing what should be identified as a node token. In this case we ask for (?xi) ^ big $.
The regular expression (?xi) ^ big $ asks for the beginning of a line, followed by ‘big’, followed by the end of the line. When the corpus is tokenized, as is the case for freqlist() and surf_cooc(), but not for conc(), one line corresponds to one token: we are asking for tokens that match big exactly.
The rest of the arguments are the same that were set in freqlist(), as explained in Section 1.2.
coocs <- fnames_BASE %>%
surf_cooc("(?xi) ^ big $",
re_token_splitter = r"--[(?xi) \s+ ]--",
re_drop_token = r"--[(?xi) [:\[\]] ]--",
file_encoding = "windows-1252")
coocs$target_freqlist
coocs$ref_freqlistFrequency list (types in list: 1013, tokens in list: 3949)
rank type abs_freq nrm_freq
---- ----- -------- --------
1 a 314 795.1
2 the 218 552.0
3 of 100 253.2
4 and 91 230.4
5 in 87 220.3
6 er 81 205.1
7 is 81 205.1
8 you 62 157.0
9 to 61 154.5
10 this 54 136.7
11 one 51 129.1
12 it 44 111.4
13 it's 43 108.9
14 very 42 106.4
15 that 41 103.8
16 so 40 101.3
17 how 34 86.1
18 be 32 81.0
19 there 31 78.5
20 but 29 73.4
...Frequency list (types in list: 36957, tokens in list: 1619982)
rank type abs_freq nrm_freq
---- ---- -------- --------
1 the 87002 537.1
2 of 49165 303.5
3 and 45143 278.7
4 to 42801 264.2
5 er 39446 243.5
6 a 36117 222.9
7 that 31847 196.6
8 in 30306 187.1
9 you 29482 182.0
10 is 26001 160.5
11 it 20399 125.9
12 i 16901 104.3
13 so 16865 104.1
14 this 14914 92.1
15 we 13149 81.2
16 have 10339 63.8
17 what 10281 63.5
18 on 10202 63.0
19 be 10172 62.8
20 but 10151 62.7
...The object coocs is a cooc_info object, i.e. a list of two frequency lists: a target frequency list with the co-occurrence frequencies of items in the vicinity of the node big (by default, 3 tokens to either side), and a reference frequency list with the frequencies of items in the rest of the corpus.
3.1 Association scores
Next, we calculate the association score with a call to assoc_scores(), providing the full object coocs instead of the separated frequency lists. We store the result in a variable called scores_colloc. Once we have our scores_colloc, we can sort them by PMI and by signed \(G^2\).
# calculate scores
scores_colloc <- assoc_scores(coocs)
# print scores, sorted by PMI
print(scores_colloc, sort_order = "PMI")Association scores (types in list: 220, sort order criterion: PMI)
type a PMI G_signed| b c d dir exp_a DP_rows
1 shiny 3 7.95 29.4|3946 2 1619980 1 0.012 0.001
2 toe 3 7.95 29.4|3946 2 1619980 1 0.012 0.001
3 bang 6 6.95 47.9|3943 14 1619968 1 0.049 0.002
4 premium 3 6.02 19.6|3946 16 1619966 1 0.046 0.001
5 organisations 5 5.88 31.6|3944 30 1619952 1 0.085 0.001
6 corporations 3 5.57 17.6|3946 23 1619959 1 0.063 0.001
7 multinational 3 5.10 15.6|3946 33 1619949 1 0.088 0.001
8 climate 4 4.83 19.3|3945 54 1619928 1 0.141 0.001
9 twice 4 4.83 19.3|3945 54 1619928 1 0.141 0.001
10 philosophical 3 4.81 14.4|3946 41 1619941 1 0.107 0.001
11 gap 5 4.58 22.4|3944 81 1619901 1 0.209 0.001
12 l 3 4.46 13.0|3946 53 1619929 1 0.136 0.001
13 tests 4 4.26 16.2|3945 82 1619900 1 0.209 0.001
14 vessels 3 4.20 11.9|3946 64 1619918 1 0.163 0.001
15 difference 19 4.17 74.9|3930 414 1619568 1 1.053 0.005
16 river 3 4.16 11.8|3946 66 1619916 1 0.168 0.001
17 debate 4 4.10 15.3|3945 92 1619890 1 0.233 0.001
18 box 4 4.07 15.2|3945 94 1619888 1 0.238 0.001
19 assumption 5 3.92 18.0|3944 131 1619851 1 0.331 0.001
20 dictionary 3 3.78 10.2|3946 87 1619895 1 0.219 0.001
...
<number of extra columns to the right: 7># print scores, sorted by G_signed
print(scores_colloc, sort_order = "G_signed")Association scores (types in list: 220, sort order criterion: G_signed)
type a PMI G_signed| b c d dir exp_a
1 a 314 1.83 358.7|3635 36117 1583865 1 88.591
2 difference 19 4.17 74.9|3930 414 1619568 1 1.053
3 problem 22 2.94 51.7|3927 1159 1618823 1 2.872
4 bang 6 6.95 47.9|3943 14 1619968 1 0.049
5 one 51 1.56 43.5|3898 7041 1612941 1 17.246
6 really 29 2.16 42.2|3920 2633 1617349 1 6.473
7 quite 25 2.32 40.7|3924 2033 1617949 1 5.005
8 very 42 1.67 40.0|3907 5387 1614595 1 13.202
9 how 34 1.89 39.8|3915 3734 1616248 1 9.163
10 organisations 5 5.88 31.6|3944 30 1619952 1 0.085
11 shiny 3 7.95 29.4|3946 2 1619980 1 0.012
12 toe 3 7.95 29.4|3946 2 1619980 1 0.012
13 there's 24 1.79 25.7|3925 2822 1617160 1 6.921
14 thank 8 3.61 25.6|3941 261 1619721 1 0.654
15 too 12 2.75 25.5|3937 722 1619260 1 1.785
16 gap 5 4.58 22.4|3944 81 1619901 1 0.209
17 great 10 2.80 21.8|3939 582 1619400 1 1.440
18 companies 6 3.72 20.0|3943 181 1619801 1 0.455
19 premium 3 6.02 19.6|3946 16 1619966 1 0.046
20 climate 4 4.83 19.3|3945 54 1619928 1 0.141
...
<number of extra columns to the right: 8>3.2 Filtering of collocates by PMI and signed \(G^2\)
We’ll use filter() to filter the collocates (i.e. the object scores_colloc) by PMI and signed \(G\), store the result in a variable called top_scores_colloc and print the result, first sorted by PMI, then by signed \(G^2\). This allows us to explore which words are ranked higher by each of the measures.
top_scores_colloc <- scores_colloc %>%
filter(PMI >= 2 & G_signed >= 2)
# print top_scores_colloc, sorted by PMI
top_scores_colloc %>%
print(sort_order = "PMI")Association scores (types in list: 61, sort order criterion: PMI)
type a PMI G_signed| b c d dir exp_a DP_rows
1 shiny 3 7.95 29.4|3946 2 1619980 1 0.012 0.001
2 toe 3 7.95 29.4|3946 2 1619980 1 0.012 0.001
3 bang 6 6.95 47.9|3943 14 1619968 1 0.049 0.002
4 premium 3 6.02 19.6|3946 16 1619966 1 0.046 0.001
5 organisations 5 5.88 31.6|3944 30 1619952 1 0.085 0.001
6 corporations 3 5.57 17.6|3946 23 1619959 1 0.063 0.001
7 multinational 3 5.10 15.6|3946 33 1619949 1 0.088 0.001
8 climate 4 4.83 19.3|3945 54 1619928 1 0.141 0.001
9 twice 4 4.83 19.3|3945 54 1619928 1 0.141 0.001
10 philosophical 3 4.81 14.4|3946 41 1619941 1 0.107 0.001
11 gap 5 4.58 22.4|3944 81 1619901 1 0.209 0.001
12 l 3 4.46 13.0|3946 53 1619929 1 0.136 0.001
13 tests 4 4.26 16.2|3945 82 1619900 1 0.209 0.001
14 vessels 3 4.20 11.9|3946 64 1619918 1 0.163 0.001
15 difference 19 4.17 74.9|3930 414 1619568 1 1.053 0.005
16 river 3 4.16 11.8|3946 66 1619916 1 0.168 0.001
17 debate 4 4.10 15.3|3945 92 1619890 1 0.233 0.001
18 box 4 4.07 15.2|3945 94 1619888 1 0.238 0.001
19 assumption 5 3.92 18.0|3944 131 1619851 1 0.331 0.001
20 dictionary 3 3.78 10.2|3946 87 1619895 1 0.219 0.001
...
<number of extra columns to the right: 7>Association scores (types in list: 61, sort order criterion: G_signed)
type a PMI G_signed| b c d dir exp_a DP_rows
1 difference 19 4.17 74.9|3930 414 1619568 1 1.053 0.005
2 problem 22 2.94 51.7|3927 1159 1618823 1 2.872 0.005
3 bang 6 6.95 47.9|3943 14 1619968 1 0.049 0.002
4 really 29 2.16 42.2|3920 2633 1617349 1 6.473 0.006
5 quite 25 2.32 40.7|3924 2033 1617949 1 5.005 0.005
6 organisations 5 5.88 31.6|3944 30 1619952 1 0.085 0.001
7 shiny 3 7.95 29.4|3946 2 1619980 1 0.012 0.001
8 toe 3 7.95 29.4|3946 2 1619980 1 0.012 0.001
9 thank 8 3.61 25.6|3941 261 1619721 1 0.654 0.002
10 too 12 2.75 25.5|3937 722 1619260 1 1.785 0.003
11 gap 5 4.58 22.4|3944 81 1619901 1 0.209 0.001
12 great 10 2.80 21.8|3939 582 1619400 1 1.440 0.002
13 companies 6 3.72 20.0|3943 181 1619801 1 0.455 0.001
14 premium 3 6.02 19.6|3946 16 1619966 1 0.046 0.001
15 climate 4 4.83 19.3|3945 54 1619928 1 0.141 0.001
16 twice 4 4.83 19.3|3945 54 1619928 1 0.141 0.001
17 assumption 5 3.92 18.0|3944 131 1619851 1 0.331 0.001
18 corporations 3 5.57 17.6|3946 23 1619959 1 0.063 0.001
19 area 8 2.78 17.2|3941 472 1619510 1 1.167 0.002
20 market 10 2.39 17.0|3939 776 1619206 1 1.911 0.002
...
<number of extra columns to the right: 7>4 Post-processing
The rest of the steps can be applied to any assoc_scores object, i.e. either the output of a keyword analysis or that of a collocation analysis.
4.1 Saving the results to file
We can use write_assoc() to write an assoc_scores object to a file. That file is a tab delimited text file. It can easily be imported in spreadsheet tools but also be read again in RStudio, in future sessions, with read_assoc().
top_scores_kw %>%
write_assoc("ahlct001_top_keywords.csv")
# top_scores_kw <- read_assoc("ahlct001_top_keywords.csv")
top_scores_colloc %>%
write_assoc("big_top_collocates.csv")
# top_scores_colloc <- read_assoc("big_top_collocates.csv")4.2 A nicer way of showing the scores in a report
We can turn the scores into a tibble with the function as_tibble(). This allows people familiar with the tidyverse to use the rich set of tidyverse functions that are applicable to tibbles.
In Table 2 we print the top thirty keywords (according to PMI, and sorted by descending PMI) the tidyverse way:
top_scores_kw %>% # also valid for top_scores_colloc
as_tibble() %>%
select(type, a, PMI, G_signed) %>% # select 4 columns
arrange(desc(PMI)) %>% # sort by PMI (descending)
head(30) %>% # select top 30 rows
kbl(col.names = c("Type", "Frequency", "PMI", r"(Signed $G^2$)")) %>%
kable_minimal() %>%
scroll_box(height = "400px")| Type | Frequency | PMI | Signed $G^2$ |
|---|---|---|---|
| manu | 15.5 | 7.25 | 152.3 |
| gladstone | 13.5 | 7.24 | 132.2 |
| rohini | 10.5 | 7.23 | 102.1 |
| troilus | 9.5 | 7.22 | 92.1 |
| thistlewood | 7.5 | 7.20 | 72.1 |
| guyanese | 6.5 | 7.19 | 62.1 |
| stillborn | 6.5 | 7.19 | 62.1 |
| cabin | 5.5 | 7.17 | 52.2 |
| kampta | 5.5 | 7.17 | 52.2 |
| guyana | 9.0 | 7.14 | 84.5 |
| anarch | 4.5 | 7.14 | 42.3 |
| aperture | 4.5 | 7.14 | 42.3 |
| coolie | 4.5 | 7.14 | 42.3 |
| criseyde | 4.5 | 7.14 | 42.3 |
| ellar | 4.5 | 7.14 | 42.3 |
| grandpa | 4.5 | 7.14 | 42.3 |
| kaka | 4.5 | 7.14 | 42.3 |
| lachrimae | 4.5 | 7.14 | 42.3 |
| overboard | 4.5 | 7.14 | 42.3 |
| awakened | 7.0 | 7.10 | 64.8 |
| beatings | 3.5 | 7.10 | 32.4 |
| booths | 3.5 | 7.10 | 32.4 |
| diomede | 3.5 | 7.10 | 32.4 |
| ellar's | 3.5 | 7.10 | 32.4 |
| gladstone's | 3.5 | 7.10 | 32.4 |
| jamaican | 3.5 | 7.10 | 32.4 |
| melody | 3.5 | 7.10 | 32.4 |
| miriam's | 3.5 | 7.10 | 32.4 |
| mist | 3.5 | 7.10 | 32.4 |
| paki | 3.5 | 7.10 | 32.4 |
We can do the same sorting by signed \(G^2\) instead, as shown in Table 3:
top_scores_colloc %>% # also valid for top_scores_kw
as_tibble() %>%
select(type, a, PMI, G_signed) %>% # select 4 columns
arrange(desc(G_signed)) %>% # sort by G_signed (descending)
head(30) %>% # select top 30 rows
kbl(col.names = c("Type", "Frequency", "PMI", r"(Signed $G^2$)")) %>%
kable_minimal() %>%
scroll_box(height = "400px")| Type | Frequency | PMI | Signed $G^2$ |
|---|---|---|---|
| difference | 19 | 4.17 | 74.9 |
| problem | 22 | 2.94 | 51.7 |
| bang | 6 | 6.95 | 47.9 |
| really | 29 | 2.16 | 42.2 |
| quite | 25 | 2.32 | 40.7 |
| organisations | 5 | 5.88 | 31.6 |
| shiny | 3 | 7.95 | 29.4 |
| toe | 3 | 7.95 | 29.4 |
| thank | 8 | 3.61 | 25.6 |
| too | 12 | 2.75 | 25.5 |
| gap | 5 | 4.58 | 22.4 |
| great | 10 | 2.80 | 21.8 |
| companies | 6 | 3.72 | 20.0 |
| premium | 3 | 6.02 | 19.6 |
| climate | 4 | 4.83 | 19.3 |
| twice | 4 | 4.83 | 19.3 |
| assumption | 5 | 3.92 | 18.0 |
| corporations | 3 | 5.57 | 17.6 |
| area | 8 | 2.78 | 17.2 |
| market | 10 | 2.39 | 17.0 |
| issue | 7 | 2.96 | 16.6 |
| question | 11 | 2.19 | 16.3 |
| tests | 4 | 4.26 | 16.2 |
| multinational | 3 | 5.10 | 15.6 |
| debate | 4 | 4.10 | 15.3 |
| box | 4 | 4.07 | 15.2 |
| such | 9 | 2.35 | 15.0 |
| company | 5 | 3.38 | 14.5 |
| philosophical | 3 | 4.81 | 14.4 |
| enough | 7 | 2.66 | 14.1 |
4.3 Plotting the association scores
If we store the tibble version of the results in a variable, such as top_scores_df, we can reuse that object in several subsequent instructions without having to recreate it time and again. Let’s work with the keywords here.
top_scores_df <- as_tibble(top_scores_kw)To illustrate the use of the tibble version of the results, we can, for instance, generate plots on the basis of the object top_scores_df. Our base plot will map the signed \(G^2\) values on the x-axis and the PMI scores on the y-axis. We’ll also set a common theme to all plots with theme_set().
In Figure 1, we build a simple scatter plot with points representing the different words. The plot gives us an idea of to which extent both measures correlate.
g + geom_point()
We see that the measures do correlate a bit, but definitely not perfectly. In fact, should you build similar plots for other combinations of measures, you’ll find that some pair correlate much more clearly than what we see here.
Let’s inspect to which extent absolute frequencies can explain the discrepancies between PMI and signed \(G^2\). In Figure 2 we have the frequencies in the target corpus (i.e. the values in the a cell of the contingency tables) mapped to the size of the symbols. We see that high frequencies tend to relatively boost signed G scores and that low frequencies appear to relatively increase the probability of obtaining a high PMI score.
g + geom_point(aes(size = a))
We can also plot the names of the words instead of using symbols, using the geom_text() function, as shown in Figure 3.
top_scores_df the names of the types are stored in a column called type.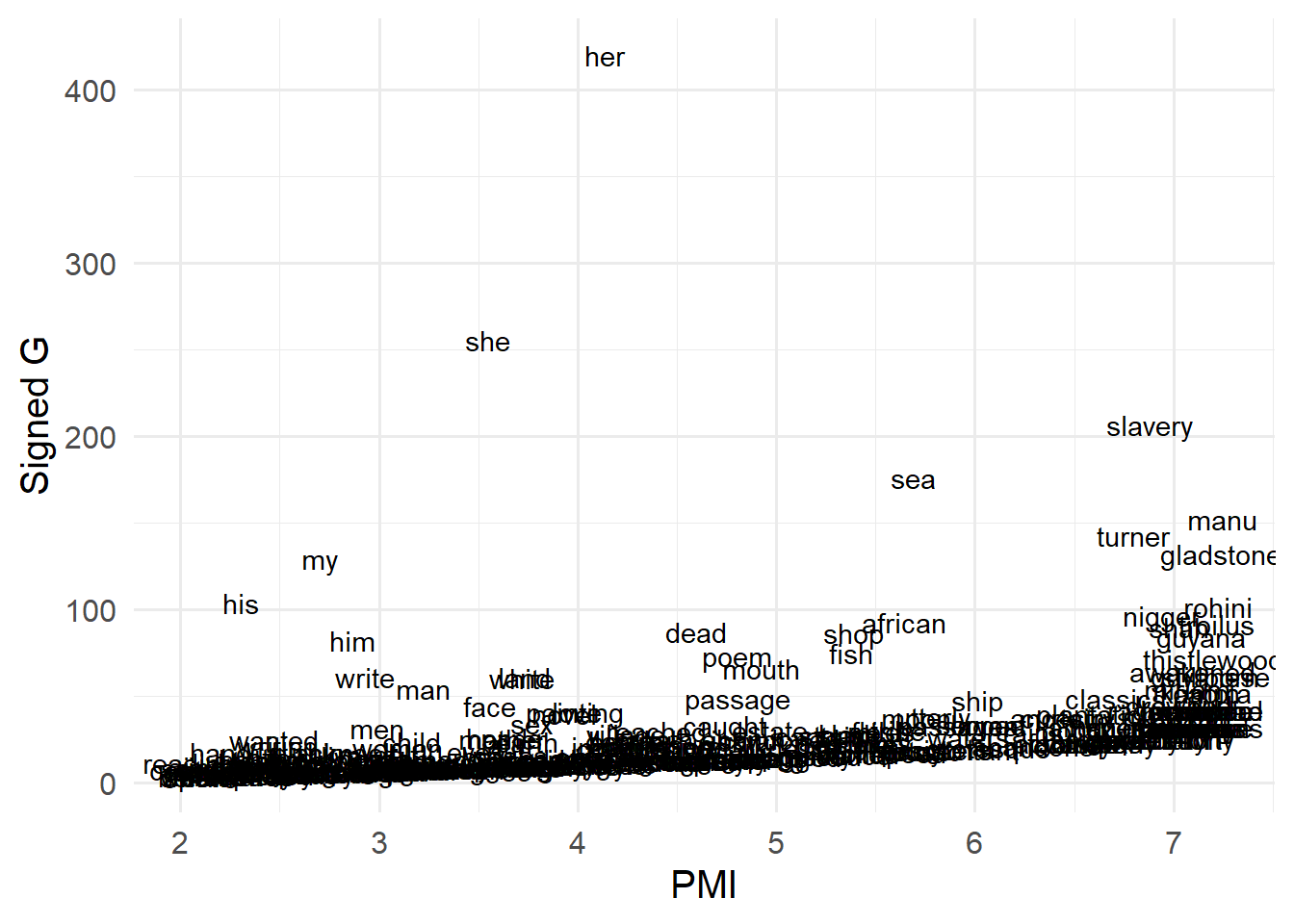
For a more sophisticated plot, the ggrepel package allows us to add text close to the position of their datapoints, avoiding overlap. To create Figure 4 we define a smaller dataframe with the subset of keywords for which \(G^2\) is larger than 100 and provide it as data for ggrepel::geom_text_repel(). The x and y aesthetics are inherited from the ggplot() call in g.
high_G_signed <- top_scores_df %>%
filter(G_signed > 100) # extract types with high G_signed
g + geom_point() +
ggrepel::geom_text_repel(data = high_G_signed, aes(label = type))